Id,InvoiceNum,InvoiceDate,BillTo,ShipTo
1,ABC123,2018-01-15 00:00:00.000,Lynn Hess,"Herman Trisler, 4189 Oak Drive"
2,XYZ987,2017-06-23 00:00:00.000,Yvonne Pollak,"Clarence Burton, 1470 Cost Avenue"
3,FOO777,2018-01-02 00:00:00.000,Phillip Freeman,"Ronda Snell, 4685 Valley Lane"Posts tagged with 'SQL'
This is a repost that originally appeared on the Couchbase Blog: CSV tooling for migrating to Couchbase from Relational.
CSV (Comma-seperated values) is a file format that can be exported from a relational database (like Oracle or SQL Server). It can then be imported into Couchbase Server with the cbimport utility.
Note: cbimport comes with Couchbase Enterprise Edition. For Couchbase Community Edition, you can use the more limited cbtransfer tool or go with cbdocloader if JSON is an option.
A straight relational→CSV→Couchbase ETL probably isn’t going to be the complete solution for data migration. In a later post, I’ll write about data modeling decisions that you’ll have to consider. But it’s a starting point: consider this data as "staged".
Note: for this post, I’m using SQL Server and a Couchbase Server cluster, both installed locally. The steps will be similar for SQL Server, Oracle, MySQL, PostgreSQL, etc.
Export to CSV
The first thing you need to do is export to CSV. I have a relational database with two tables: Invoices and InvoiceItems.
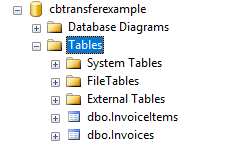
I’m going to export the data from these two tables into two CSV files. With SQL Server Management Studio, this can be done a number of different ways. You can use sqlcmd or bcp at the command line. Or you can use Powershell’s Invoke-Sqlcmd and pipe it through Export-Csv. You can also use the SQL Server Management Studio UI.
Other relational databases will have command line utilities, UI tools, etc to export CSV.
Here is an example of a CSV export from a table called "Invoices":
Here’s an export from a related table called "InvoiceItems":
InvoiceId,Product,Quantity,Price
1,Tire,2,20.00
1,Steering Wheel,5,10.00
1,Engine Oil,10,15.00
1,Brake Pad,24,1000.00
2,Mouse pad,1,3.99
2,Mouse,1,14.99
2,Computer monitor,1,199.98
3,Cupcake,12,.99
3,Birthday candles,1,.99
3,Delivery,1,30.00Load CSV into Couchbase
Let’s import these into a Couchbase bucket. I’ll assume you’ve already created an empty bucket named "staging".
First, let’s import invoices.csv.
Loading invoices
C:\Program Files\Couchbase\Server\bin\cbimport csv -c localhost -u Administrator -p password -b staging -d file://invoices.csv --generate-key invoice::%Id%Note: with Linux/Mac, instead of C:\Program Files\Couchbase\Server\bin, the path will be different.
Let’s break this down:
-
cbimport: This is the command line utility you’re using
-
csv: We’re importing from a CSV file. You can also import from JSON files.
-
-c localhost: The location of your Couchbase Server cluster.
-
-u Administrator -p password: Credentials for your cluster. Hopefully you have more secure credentials than this example!
-
-b staging: The name of the Couchbase bucket you want the data to end up in
-
--generate-key invoice::%Id% The template that will be used to create unique keys in Couchbase. Each line of the CSV will correspond to a single document. Each document needs a unique key. I decided to use the primary key (integer) with a prefix indicating that it’s an invoice document.
The end result of importing a 3 line file is 3 documents:

At this point, the staging bucket only contains invoice documents, so you may want to perform transformations now. I may do this in later modeling examples, but for now let’s move on to the next file.
Loading invoice items
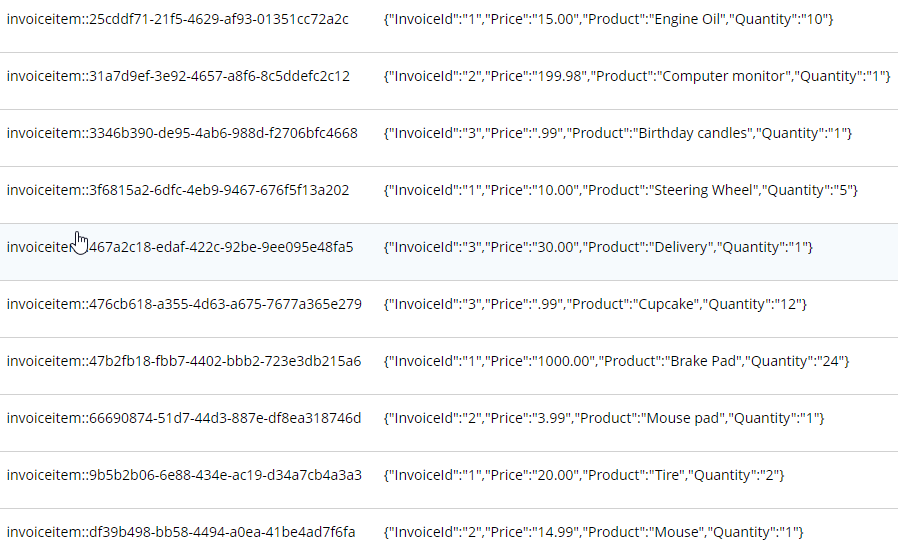
C:\Program Files\Couchbase\Server\bin\cbimport csv -c localhost -u Administrator -p password -b staging -d file://invoice_items.csv --generate-key invoiceitem::#UUID#This is nearly identical to the last import. One difference is that it’s a new file (invoice_items.csv). But the most important difference is --generate—key. These records only contain foreign keys, but each document in Couchbase must have a unique key. Ultimately, we may decide to embed these records into their parent Invoice documents. But for now I decided to use UUID to generate unique keys for the records.
The end result of importing this 10 line file is 10 more documents:
What’s next?
Once you have a CSV file, it’s very easy to get data into Couchbase. However, this sort of direct translation is often not going to be enough on its own. I’ve explored some aspects of data modeling in a previous blog post on migrating from SQL Server, but I will revisit this Invoices example in a refresher blog post soon.
In the meantime, be sure to check out How Couchbase Beats Oracle for more information on why companies are replacing Oracle for certain use cases. And also take a look at the Moving from Relational to NoSQL: How to Get Started white paper.
If you have any questions or comments, please feel free to leave them here, contact me on Twitter @mgroves, or ask your question in the Couchbase Forums.
This is a repost that originally appeared on the Couchbase Blog: Aggregate grouping with N1QL or with MapReduce.
Aggregate grouping is what I’m titling this blog post, but I don’t know if it’s the best name. Have you ever used MySQL’s GROUP_CONCAT function or the FOR XML PATH('') workaround in SQL Server? That’s basically what I’m writing about today. With Couchbase Server, the easiest way to do it is with N1QL’s ARRAY_AGG function, but you can also do it with an old school MapReduce View.
I’m writing this post because one of our solution engineers was working on this problem for a customer (who will go unnamed). Neither of us could find a blog post like this with the answer, so after we worked together to come up with a solution, I decided I would blog about it for my future self (which is pretty much the main reason I blog anything, really. The other reason is to find out if anyone else knows a better way).
Before we get started, I’ve made some material available if you want to follow along. The source code I used to generate the "patient" data used in this post is available on GitHub. If you aren’t .NET savvy, you can just use cbimport on sample data that I’ve created. (Or, you can use the N1QL sandbox, more information on that later). The rest of this blog post assumes you have a "patients" bucket with that sample data in it.
Requirements
I have a bucket of patient documents. Each patient has a single doctor. The patient document refers to a doctor by a field called doctorId. There may be other data in the patient document, but we’re mainly focused on the patient document’s key and the doctorId value. Some examples:
key 01257721
{
"doctorId": 58,
"patientName": "Robyn Kirby",
"patientDob": "1986-05-16T19:01:52.4075881-04:00"
}
key 116wmq8i
{
"doctorId": 8,
"patientName": "Helen Clark",
"patientDob": "2016-02-01T04:54:30.3505879-05:00"
}Next, we can assume that each doctor can have multiple patients. We can also assume that a doctor document exists, but we don’t actually need that for this tutorial, so let’s just focus on the patients for now.
Finally, what we want for our application (or report or whatever), is an aggregate grouping of the patients with their doctor. Each record would identify a doctor and a list/array/collection of patients. Something like:
| doctor | patients |
|---|---|
|
58 |
01257721, 450mkkri, 8g2mrze2 … |
|
8 |
05woknfk, 116wmq8i, 2t5yttqi … |
|
… etc … |
… etc … |
This might be useful for a dashboard showing all the patients assigned to doctors, for instance. How can we get the data in this form, with N1QL or with MapReduce?
N1QL Aggregate grouping
N1QL gives us the ARRAY_AGG function to make this possible.
Start by selecting the doctorId from each patient document, and the key to the patient document. Then, apply ARRAY_AGG to the patient document ID. Finally, group the results by the doctorId.
SELECT p.doctorId AS doctor, ARRAY_AGG(META(p).id) AS patients
FROM patients p
GROUP BY p.doctorId;Note: don’t forget to run CREATE PRIMARY INDEX ON patients for this tutorial to enable a primary index scan.
Imagine this query without the ARRAY_AGG. It would return one record for each patient. By adding the ARRAY_AGG and the GROUP BY, it now returns one record for each doctor.
Here’s a snippet of the results on the sample data set I created:
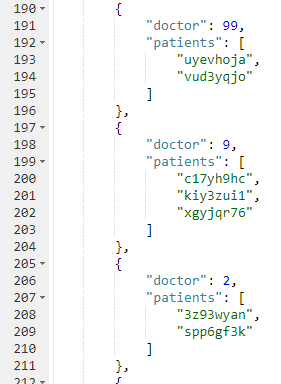
If you don’t want to go through the trouble of creating a bucket and importing sample data, you can also try this in the N1QL tutorial sandbox. There aren’t patient documents in there, so the query will be a little different.
I’m going to group up emails by age. Start by selecting the age from each document, and the email from each document. Then, apply ARRAY_AGG to the email. Finally, group the results by the age.
SELECT t.age AS age, ARRAY_AGG(t.email) AS emails
FROM tutorial t
group by t.age;Here’s a screenshot of some of the results from the sandbox:

Aggregate group with MapReduce
Similar aggregate grouping can also be achieved with a MapReduce View.
Start by creating a new View. From Couchbase Console, go to Indexes, then Views. Select the "patients" bucket. Click "Create Development View". Name a design document (I called mine "_design/dev_patient". Create a view, I called mine "doctorPatientGroup".
We’ll need both a Map and a custom Reduce function.
First, for the map, we just want the doctorId (in an array, since we’ll be using grouping) and the patient’s document ID.
function (doc, meta) {
emit([doc.doctorId], meta.id);
}Next, for the reduce function, we’ll take the values and concatenate them into an array. Below is one way that you can do it. I do not claim to be a JavaScript expert or a MapReduce expert, so there might be a more efficient way to tackle this:
function reduce(key, values, rereduce) {
var merged = [].concat.apply([], values);
return merged;
}After you’ve created both map and reduce functions, save the index.
Finally, when actually calling this Index, set group_level to 1. You can do this in the UI:
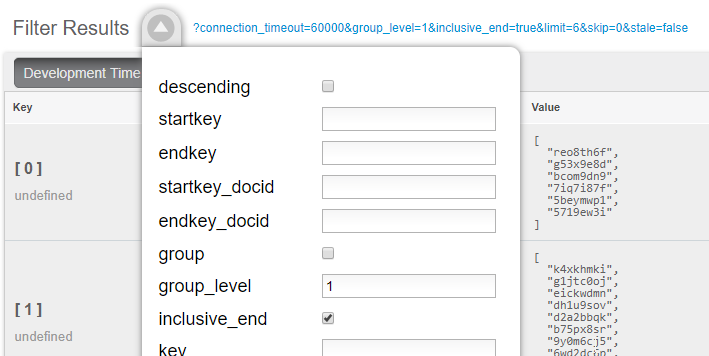
Or you can do it from the Index URL. Here’s an example from a cluster running on my local machine:
http://127.0.0.1:8092/patients/_design/dev_patients/_view/doctorPatientGroup?connection_timeout=60000&full_set=true&group_level=1&inclusive_end=true&skip=0&stale=falseThe result of that view should look like this (truncated to look nicer in a blog post):
{"rows":[
{"key":[0],"value":["reo8th6f","g53x9e8d", ... ]},
{"key":[1],"value":["k4xkhmki","g1jtc0oj", ... ]},
{"key":[2],"value":["spp6gf3k","3z93wyan"]},
{"key":[3],"value":["qnx93fh3","gssusiun", ...]},
{"key":[4],"value":["qvqgb0ve","jm0g69zz", ...]},
{"key":[5],"value":["ywjfvad6","so4uznxx", ...]}
...
]}Summary
I think the N1QL method is easier, but there may be performance benefits to using MapReduce in some cases. In either case, you can accomplish aggregate grouping just as easily (if not more easily) as in a relational database.
Interested in learning more about N1QL? Be sure to check out the complete N1QL tutorial/sandbox. Interested in MapReduce Views? Check out the MapReduce Views documentation to get started.
Did you find this post useful? Have suggestions for improvement? Please leave a comment below, or contact me on Twitter @mgroves.
This is a repost that originally appeared on the Couchbase Blog: SQL Server and Couchbase side-by-side (video).
SQL Server is compared (and contrasted) with Couchbase Server in this video.
If you are averse to video, you can check out the corresponding blog post series I wrote a few months ago that covers the same material:
The source code demonstrated in this video is available on GitHub.
If you have questions or feedback, please contact me at [email protected], or on @mgroves at Twitter, or just leave a comment below.

Eric Maxwell talks Realm's NoSQL database for mobile.
Show Notes:
- Realm.io
- The NoSQL Database Podcast
- Eric Maxwell's episode will be published in June
- Subscribe to The NoSQL Database Podcast on iTunes, or check out the podcast on LibSyn
- There was some discussion of the difference between an object database and a document database
- Realm on Github
- Eric was kind enough to share his email address in the podcast.
- #Hashtag Comedy Troupe in Columbus, Ohio
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Theme music is "Crosscutting Concerns" by The Dirty Truckers, check out their music on Amazon or iTunes.
This is a repost that originally appeared on the Couchbase Blog: SQL to JSON Data Modeling with Hackolade.
SQL to JSON data modeling is something I touched on in the first part of my "Moving from SQL Server to Couchbase" series. Since that blog post, some new tooling has come to my attention from Hackolade, who have recently added first-class Couchbase support to their tool.
In this post, I’m going to review the very simple modeling exercise I did by hand, and show how IntegrIT’s Hackolade can help.
I’m using the same SQL schema that I used in the previous blog post series; you can find it on GitHub (in the SQLServerDataAccess/Scripts folder).
Review: SQL to JSON data modeling
First, let’s review, the main way to represent relations in a relational database is via a key/foreign key relationship between tables.
When looking at modeling in JSON, there are two main ways to represent relationships:
-
Referential - Concepts are given their own documents, but reference other document(s) using document keys.
-
Denormalization - Instead of splitting data between documents using keys, group the concepts into a single document.
I started with a relational model of shopping carts and social media users.
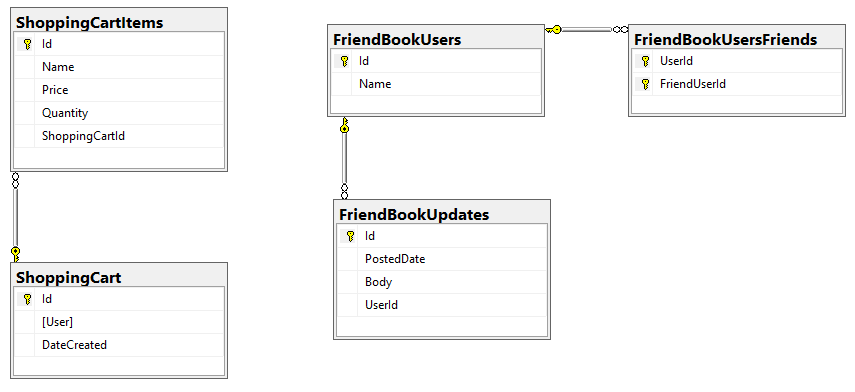
In my example, I said that a Shopping Cart - to - Shopping Cart Items relationship in a relational database would probably be better represented in JSON by a single Shopping Cart document (which contains Items). This is the "denormalization" path. Then, I suggested that a Social Media User - to - Social Media User Update relationship would be best represented in JSON with a referential relationship: updates live in their own documents, separate from the user.
This was an entirely manual process. For that simple example, it was not difficult. But with larger models, it would be helpful to have some tooling to assist in the SQL to JSON data modeling. It won’t be completely automatic: there’s still some art to it, but the tooling can do a lot of the work for us.
Starting with a SQL Server DDL
This next part assumes you’ve already run the SQL scripts to create the 5 tables: ShoppingCartItems, ShoppingCart, FriendBookUsers, FriendBookUpdates, and FriendBookUsersFriends. (Feel free to try this on your own databases, of course).
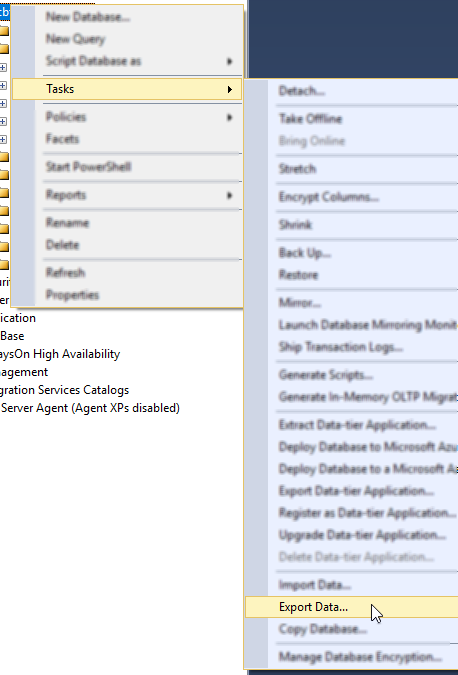
The first step is to create a DDL script of your schema. You can do this with SQL Server Management Studio.
First, right click on the database you want. Then, go to "Tasks" then "Generate Scripts". Next, you will see a wizard. You can pretty much just click "Next" on each step, but if you’ve never done this before you may want to read the instructions of each step so you understand what’s going on.
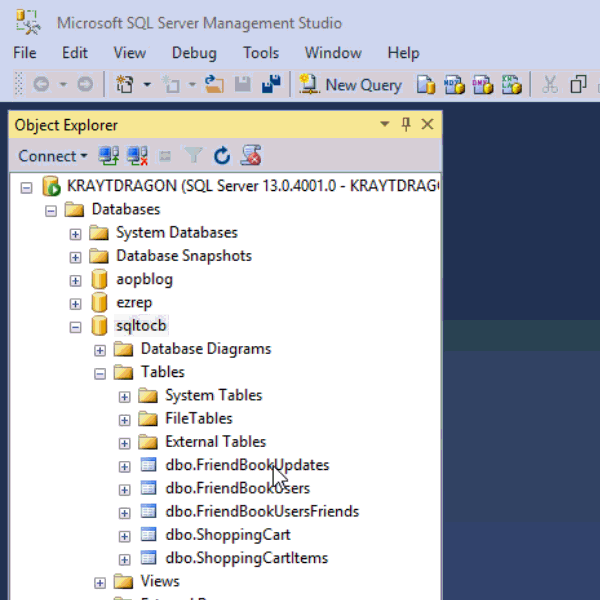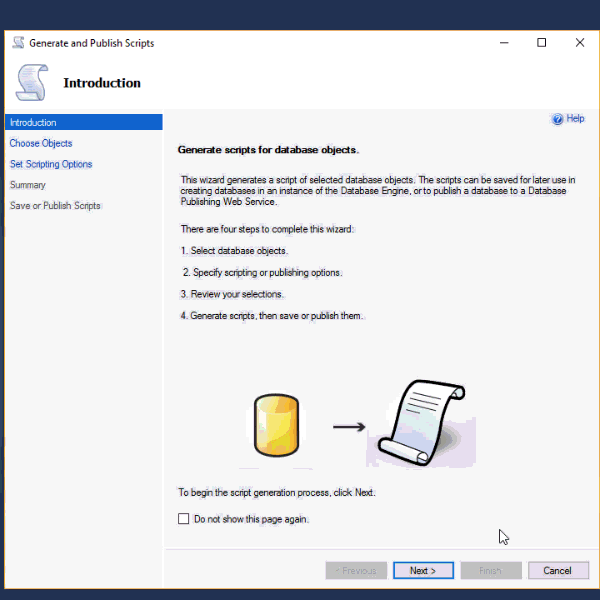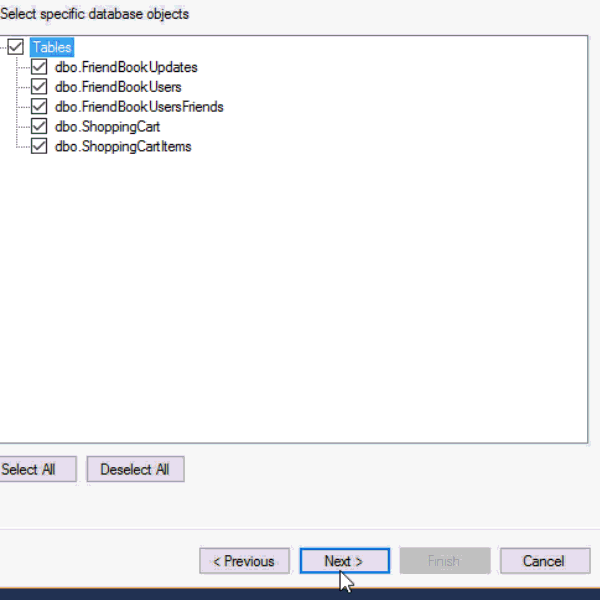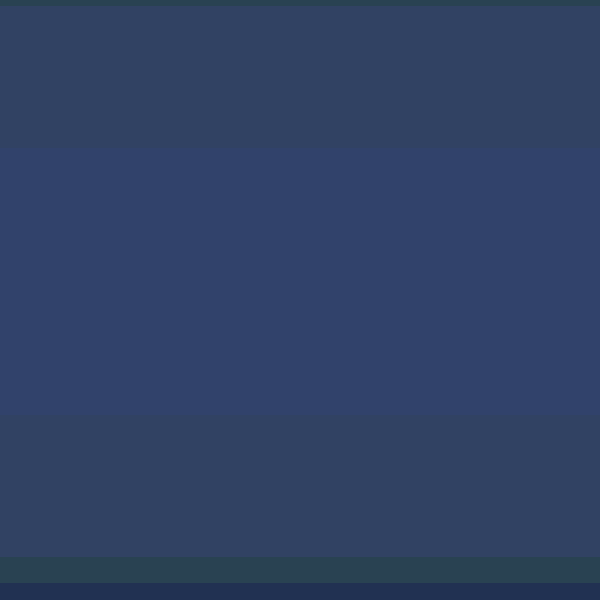
Finally, you will have a SQL file generated at the path you specified.
This will be a text file with a series of CREATE and ALTER statements in it (at least). Here’s a brief excerpt of what I created (you can find the full version on Github).
CREATE TABLE [dbo].[FriendBookUpdates](
[Id] [uniqueidentifier] NOT NULL,
[PostedDate] [datetime] NOT NULL,
[Body] [nvarchar](256) NOT NULL,
[UserId] [uniqueidentifier] NOT NULL,
CONSTRAINT [PK_FriendBookUpdates] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
-- etc...By the way, this should also work with SQL Azure databases.
Note: Hackolade works with other types of DDLs too, not just SQL Server, but also Oracle and MySQL.
Enter Hackolade
This next part assumes that you have downloaded and installed Hackolade. This feature is only available on the Professional edition of Hackolade, but there is a 30-day free trial available.
Once you have a DDL file created, you can open Hackolade.
In Hackolade, you will be creating/editing models that correspond to JSON models: Couchbase (of course) as well as DynamoDB and MongoDB. For this example, I’m going to create a new Couchbase model.
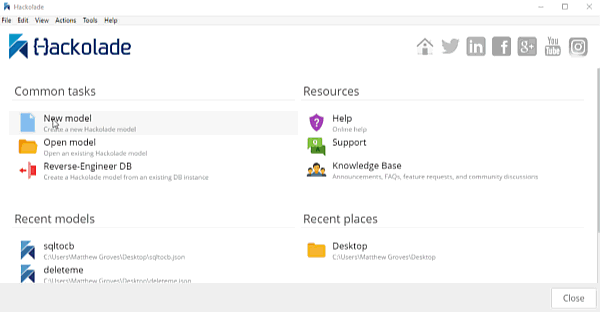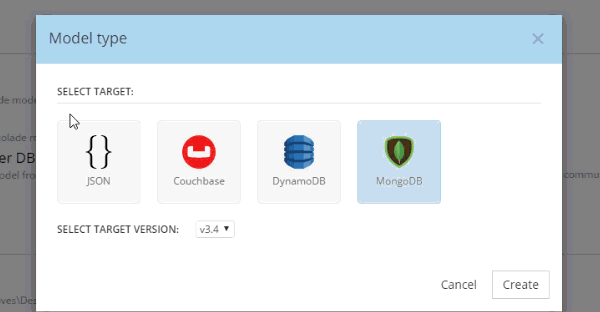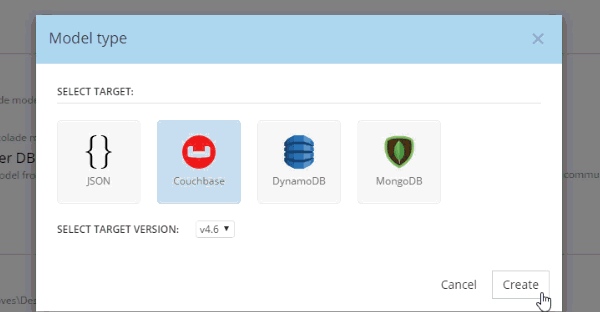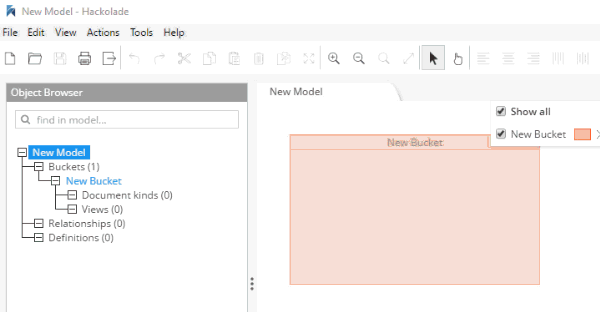
At this point, you have a brand new model that contains a "New Bucket". You can use Hackolade as a designing tool to visually represent the kinds of documents you are going to put in the bucket, the relationships to other documents, and so on.
We already have a relational model and a SQL Server DDL file, so let’s see what Hackolade can do with it.
Reverse engineer SQL to JSON data modeling
In Hackolade, go to Tools → Reverse Engineer → Data Definition Language file. You will be prompted to select a database type and a DDL file location. I’ll select "MS SQL Server" and the "script.sql" file from earlier. Finally, I’ll hit "Ok" to let Hackolade do its magic.

Hackolade will process the 5 tables into 5 different kinds of documents. So, what you end up with is very much like a literal translation.
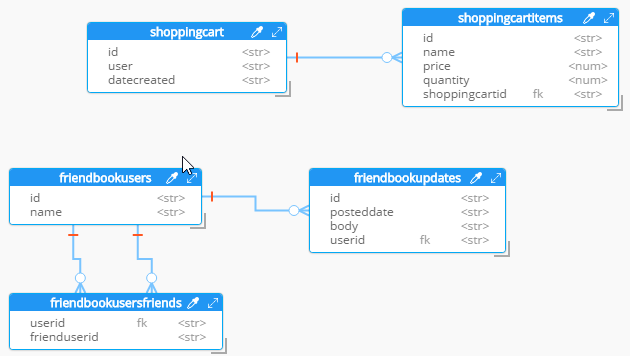
This diagram gives you a view of your model. But now you can think of it as a canvas to construct your ultimate JSON model. Hackolade gives you some tools to help.
Denormalization
For instance, Hackolade can make suggestions about denormalization when doing SQL to JSON data modeling. Go to Tools→Suggest denormalization. You’ll see a list of document kinds in "Table selection". Try selecting "shoppingcart" and "shoppingcartitems". Then, in the "Parameters" section, choose "Array in parent".
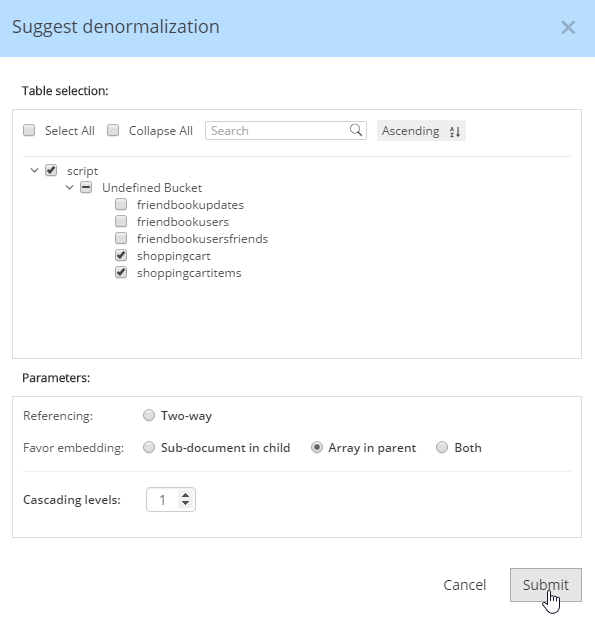
After you do this, you will see that the diagram looks different. Now, the items are embedded into an array in shoppingcart, and there are dashed lines going to shoppingcartitems. At this point, we can remove shoppingcartitems from the model (in some cases you may want to leave it, that’s why Hackolade doesn’t remove it automatically when doing SQL to JSON data modeling).
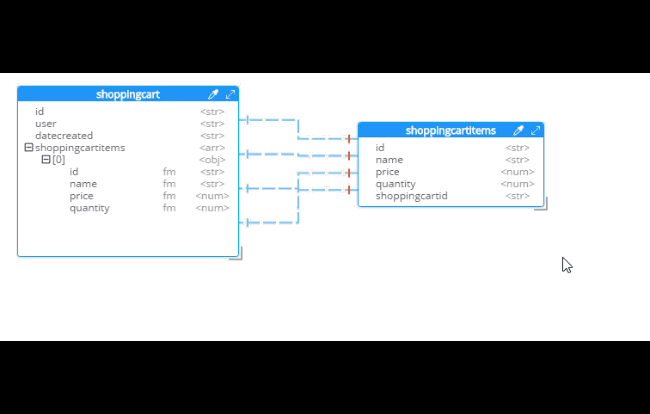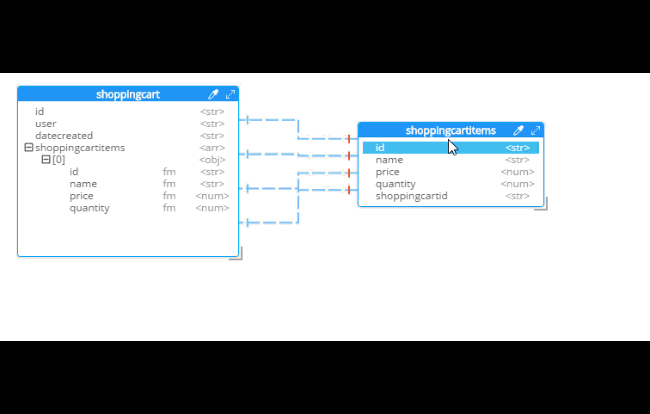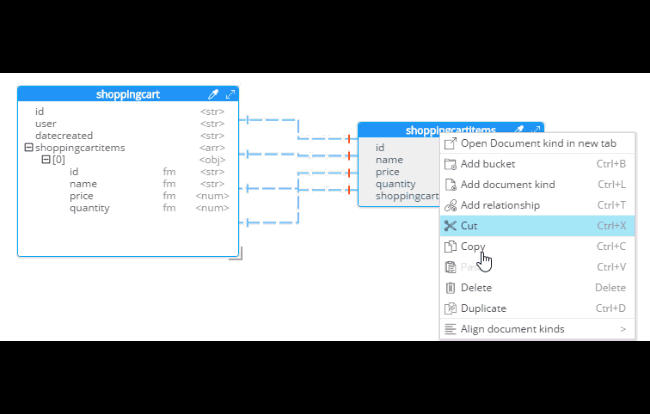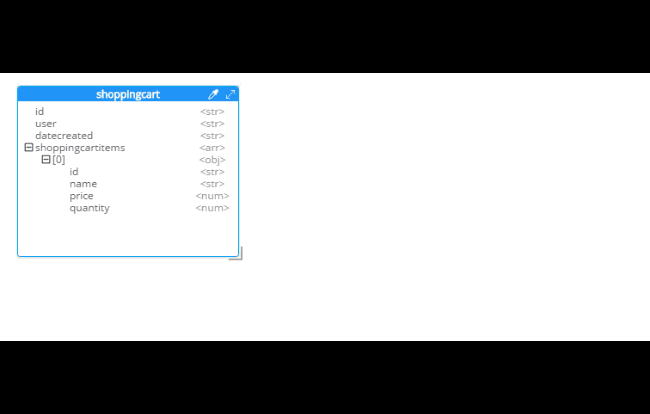
Notice that there are other options here too:
-
Embedding Array in parent - This is what was demonstrated above.
-
Embedding Sub-document in child - If you want to model the opposite way (e.g. store the shopping cart within the shopping cart item).
-
Embedding Both - Both array in parent and sub-document approach.
-
Two-way referencing - Represent a many-to-many relationship. In relational tables, this is typically done with a "junction table" or "mapping table"
Also note cascading. This is to prevent circular referencing where there can be a parent, child, grandchild, and so on. You select how far you want to cascade.
More cleanup
There are a couple of other things that I can do to clean up this model.
-
Add a 'type' field. In Couchbase, we might need to distinguish shoppingcart documents from other documents. One way to do this is to add a "discriminator" field, usually called 'type' (but you can call it whatever you like). I can give it a "default" value in Hackolade of "shoppingcart".
-
Remove the 'id' field from the embedded array. The SQL table needed this field for a foreign key relationship. Since it’s all embedded into a single document, we no longer need this field.
-
Change the array name to 'items'. Again, since a shopping cart is now consolidated into a single document, we don’t need to call it 'shoppingcartitems'. Just 'items' will do fine.

Output
A model like this can be a living document that your team works on. Hackolade models are themselves stored as JSON documents. You can share with team members, check them into source control, and so on.
You can also use Hackolade to generate static documentation about the model. This documentation can then be used to guide the development and architecture of your application.
Go to File → Generate Documentation → HTML/PDF. You can choose what components to include in your documentation.
Summary
Hackolade is a NoSQL modeling tool created by the IntegrIT company. It’s useful not only in building models from scratch, but also in reverse engineering for SQL to JSON data modeling. There are many other features about Hackolade that I didn’t cover in this post. I encourage you to download a free trial of Hackolade today. You can also find Hackolade on Twitter @hackolade.
If you have questions about Couchbase Server, please ask away in the Couchbase Forums. Also check out the Couchbase Developer Portal for more information on Couchbase for developers. Always feel free to contact me on Twitter @mgroves.
