services.AddHangfire(x => x.UseCouchbaseStorage(configuration, "familyPhotos_hangfire"));Posts tagged with '.net'
Merry Christmas! This is the last day of the C# Advent. Make sure to check out all of the other great posts from 2017 and 2018. If you want to be involved next year, look for C# Advent 2019 author sign ups at the end of October 2019, and look for blog posts to start showing up on December 1st, 2019.
What is a background job?
A background job is some code that runs apart from the normal flow of your program. It could be run asynchronously and/or on another thread. As an ASP.NET MVC developer, I tend to think of it as any task that runs outside of an MVC action being invoked.
There’s two kinds of background jobs that I’m aware of:
-
Scheduled - a task that runs every N minutes, or every Y hours, etc. This is what I’m going to show in this post today. It’s great for making periodic checks, ingesting data from some other source, etc.
-
Fire and forget - Some other piece of code kicks off a process to run in the background. It doesn’t block the code (fire), and the code doesn’t wait for a response (forget). This is great for potentially time consuming operations like checking inventory, sending emails, etc, that you don’t need a user to wait for.
What you usually need to do to create background jobs
In my experience, I’ve seen background jobs take a few different forms.
-
Separate Windows service (or Linux daemon, whatever). A console/service program that’s running in addition to your ASP.NET program. This works fine for scheduled jobs.
-
Queueing mechanisms like Kafka or Rabbit. The ASP.NET program will put messages into these queues, which will then be processed by some other program. This is fine for fire-and-forget.
-
Background jobs running within the ASP.NET process itself. In my experience, I’ve used Quartz.NET, which can run within the ASP.NET process. There’s also FluentScheduler (which I’ve not used, and doesn’t seem to come with database integration out of the box?)
With all these options in the past, I’ve experienced deployment difficulties. The wrong version of the service gets deployed, or isn’t running, or fails silently, or needs to be deployed on multiple servers in order to provide scalability/availability etc. It’s totally possible to overcome these challenges, of course. (I should also note that in my experience with Quartz.NET, I never used it in embedded form, and the last time I used it was probably 6+ years ago).
But if I just need a handful of background jobs, I’d much rather just make them part of the ASP.NET system. Yes, maybe this goes against the whole 'microservice' idea, but I don’t think it would be too hard to refactor if you decided you need to go that route. I solve my deployment problems, and as you’ll see with Hangfire (with Couchbase), it’s very easy to scale.
How hangfire works
You can find more details and documentation about Hangfire at Hangfire.io. Really, there are only three steps to setting up Hangfire with ASP.NET Core:
-
Tell ASP.NET Core about Hangfire
-
Tell Hangfire which database to use
-
Start firing off background jobs
In Startup.cs, in the ConfigureServices method:
Then, in Startup.cs, in the Configure method:
app.UseHangfireServer();I’m using Couchbase in this example, but there are options for SQL Server and other databases too. I happen to think Couchbase is a great fit, because it can easily horizontally scale to grow with your ASP.NET Core deployments. It also has a memory-first architecture for low latency storage/retrieval of job data. Generally speaking, even if you use SQL Server as your "main" database, Couchbase makes a great companion to ASP.NET or ASP.NET Core as a cache, session store, or, in this case, backing for Hangfire.
The configuration variable is to tell Hangfire where to find Couchbase:
var configuration = new ClientConfiguration
{
Servers = new List<Uri> { new Uri("http://localhost:8091") }
};
configuration.SetAuthenticator(new PasswordAuthenticator("hangfire", "password"));(In my case, it’s just running locally).
Steps 1 and 2 are down. Next, step 3 is to create some background jobs for Hangfire to process. I’ve created an ASP.NET Core app to assist me in the cataloging of all my family photographs. I want my application to scan for new files every hour or so. Here’s how I create that job in Hangfire:
RecurringJob.AddOrUpdate("photoProcessor", () => processor.ProcessAll(), Cron.Hourly);Note that I didn’t have to implement an IJob interface or anything like that. Hangfire will take any expression that you give it (at least, every expression that I’ve thrown at it so far).
Step 3 done.
Hangfire is just a NuGet package and not a separate process. So no additional deployment is needed.
How do I know it’s working?
Another great thing about Hangfire is that is comes with a built-in dashboard for the web. Back in Startup.cs, in Configure, add this code:
app.UseHangfireDashboard("/hangfire", new DashboardOptions
{
Authorization = new[] {new HangfireAuthorization()}
});I’m using my own HangfireAuthorization implementation because Hangfire only gives permission to local users by default.
Then, you get a nice dashboard right out of the box, showing you a realtime and history graph.
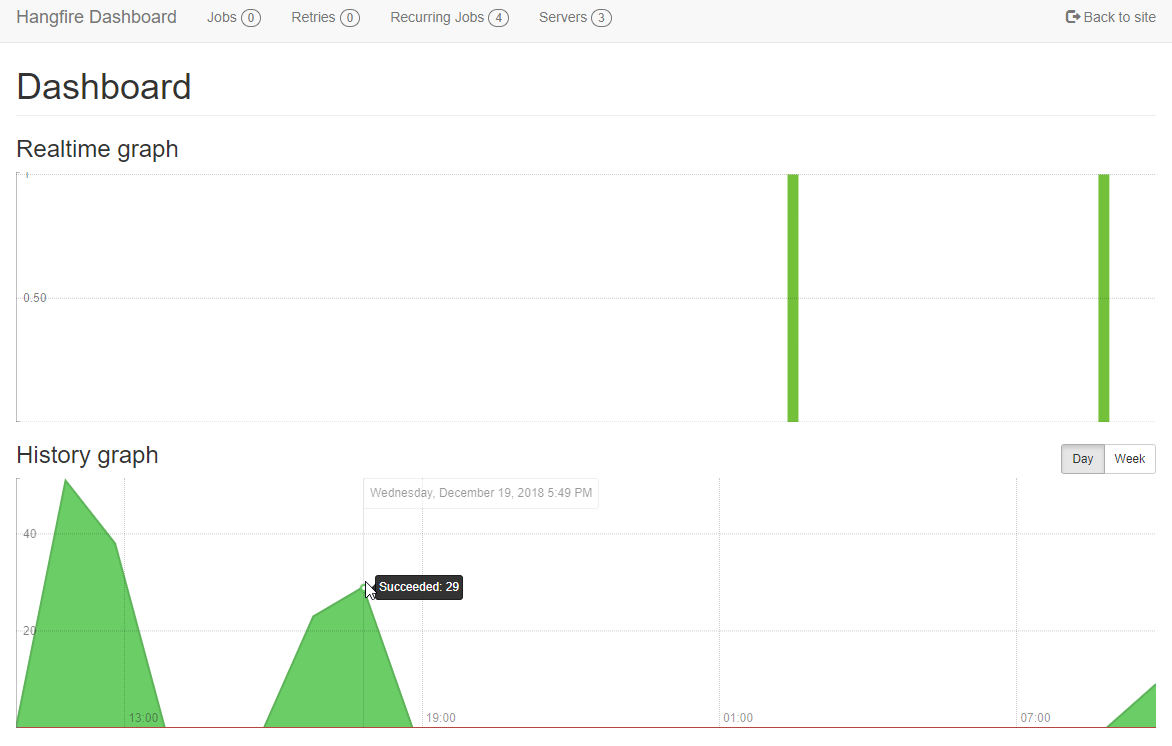
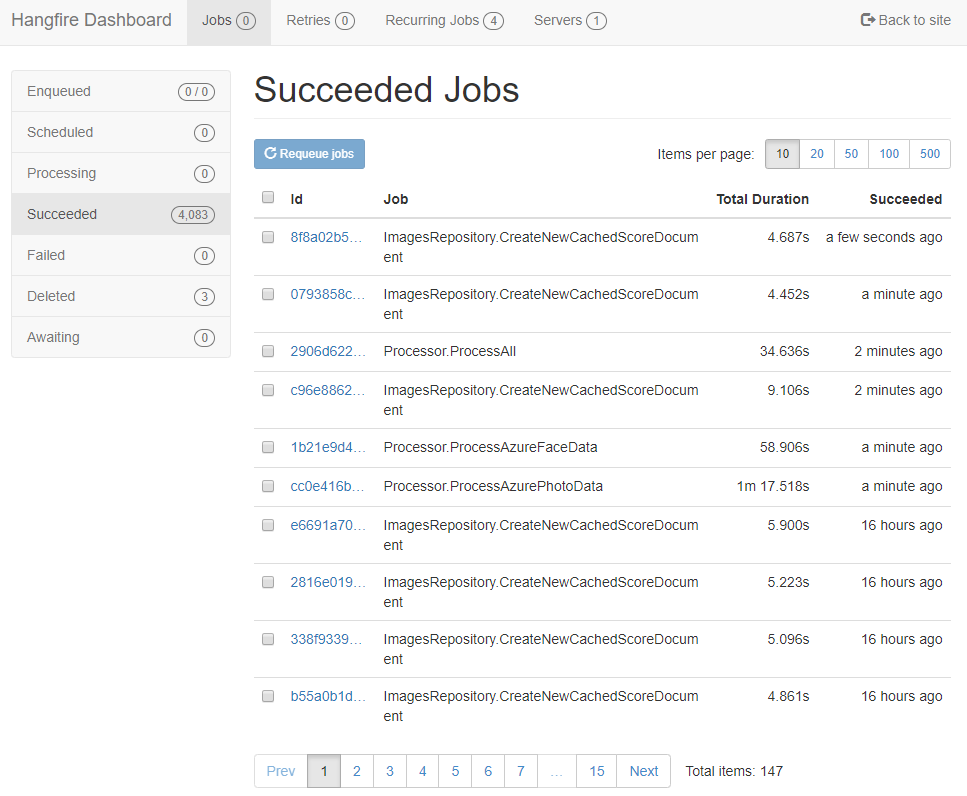
From this dashboard, you can also look at a more detailed history of what’s run and what’s failed.
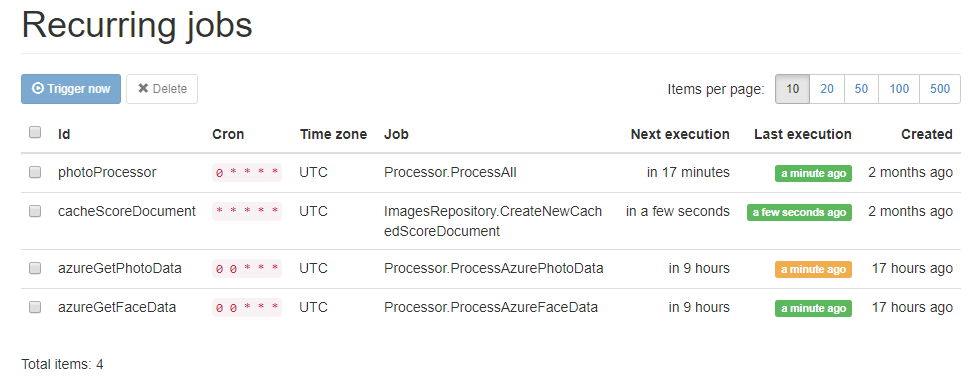
You can even kick off recurring jobs manually.
This is only the start
If you’re thinking about adding background jobs to your ASP.NET Core solution, why not give Hangfire a try?
Some more things for you to explore:
-
Scaling: every ASP.NET Core site that gets deployed with Hangfire that points to the same database will be able to process jobs too. As your ASP.NET Core site scales out, hangfire scales out with it. This is another reason that Couchbase is a good fit, because it’s also easy to scale out as your site grows.
-
Cloud: If you are deploying your site as an app service, note that Azure will shut down ASP.NET processes if they haven’t been used in a while. This means Hangfire will shut down with them. There are a couple of ways to deal with this. Check out the Hangfire documentation.
-
Retries: Hangfire will retry failed jobs. Design your background job code to expect this.
-
Hangfire Pro: The commercial version of Hangfire is called Hangfire.Pro, and it comes with some interesting looking batch capabilities. I’ve not needed any of this functionality yet, but for more advanced cases you might need this.
-
Couchbase: a NoSQL data platform that has a built-in memory-first cache layer, SQL support, text search, analytics, and more. There are lots of options for working with Couchbase in .NET. For this post, I used the Hangfire.Couchbase library (available on NuGet).

Ed Charbeneau is creating and using ASP.NET tag helpers. This episode is sponsored by Smartsheet.
Show Notes:
-
Doom and web page size: I think this was originally pointed out by Ronan Cremin
-
(Doom is a 1993 PC game, here’s a video of Doom in action)
-
I also tweeted sarcastically about page footprint and client-side rendering recently.
-
-
Progress Telerik tools
-
Vue Vixens (I couldn’t find their Rick & Morty example though)
-
Docs: Tag Helpers
-
Scott Addie is on Twitter
-
-
Demos: Telerik ASP.NET Core demos
-
Eat Sleep Code podcast (also on Soundcloud)
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Music is by Joe Ferg, check out more music on JoeFerg.com!

Jeremy Miller has created an open-source IoC tool called Lamar. This episode is sponsored by Smartsheet.
Show Notes:
-
Instead, consider Lamar for your IoC container needs.
-
At one point I was rambling about ASP.NET Core’s inability to use the service locator pattern. Some quick points:
-
Don’t use Service Locator, there are lots of other better patterns to use.
-
DO NOT DO IT.
-
If you absolutely need it: here’s a blog post about it.
-
I was incorrect in the podcast by making a sweeping statement about ASP.NET Core not having service locator. But for a very specific, narrow case where I wanted to use the service locator pattern recently, I was unable to do so. This might have been my own failing, or something that just isn’t possible with the built-in ASP.NET IoC. I have not tried this very specific, narrow use case with Lamar yet.
-
-
I plugged my book, AOP in .NET yet again.
-
Lamar is named after Mirabeau Lamar (a hero of the Texas revolution)
-
Paper: Inversion of Control Containers and the Dependency Injection pattern by Martin Fowler
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Music is by Joe Ferg, check out more music on JoeFerg.com!

Jeremy Miller is using Jasper to distribute computing. This episode is sponsored by Smartsheet.
Show Notes:
-
Nancy (NancyFx) was mentioned
- FubuMVC was mentioned too.
- TIBCO
- webMethods
- RabbitMQ as a "store and forward" queue (video)
- Azure Service Bus
- NServiceBus (from Particular Software)
- More on the Happy Meal metaphor from Jimmy Bogard
- The Oatmeal (comic)
- Jasper website - Jasper on Gitter
- Book: Enterprise Integration Patterns
- For more on Akka, check out episode 062 with Ted Neward
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Music is by Joe Ferg, check out more music on JoeFerg.com!

Craig Stuntz is manipulating .NET IL. This episode is sponsored by Smartsheet.
Show Notes:
-
Craig Stuntz was the second guest I ever had on the show. Check out Podcast 002 - Craig Stuntz on Idris
-
Craig was at CodeMash presenting with these slides
-
RuJIT was mentioned
-
I dare you to keep these straight:
-
I don’t think he mentioned it by name, but I think Fizil is the fuzzer that he’s working on.
-
SQLite created by Dr. D. Richard Hipp
-
Mono.Cecil, part of the Mono project. DNLib is another similar tool.
-
Sure, I’ll plug my book again, since we mentioned AOP. AOP in .NET
-
Obfuscation is a technique to prevent people from reverse engineering/tampering with your code. Dotfuscator is one of the tools that comes to mind.
-
Blog post: "type erasure" in Java
-
Blog post: tail calls in F#
-
The "goat behind door number 2" is a reference to the Monty Hall Paradox (which is a great discussion topic for parties)
-
Book: .NET IL Assembler by Serge Lidin
-
ECMA 335 is the Common Language Infrastructure standard. I’d like to ecma-international.org, but their site seems to be broken at the moment.
-
Good ol' LINQPad
-
Meetup: Papers We Love Columbus
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Music is by Joe Ferg, check out more music on JoeFerg.com!
