key - invoice::1
{ "BillTo": "Lynn Hess", "InvoiceDate": "2018-01-15 00:00:00.000", "InvoiceNum": "ABC123", "ShipTo": "Herman Trisler, 4189 Oak Drive" }
key - invoiceitem::1811cfcc-05b6-4ace-a52a-be3aad24dc52
{ "InvoiceId": "1", "Price": "1000.00", "Product": "Brake Pad", "Quantity": "24" }
key - invoiceitem::29109f4a-761f-49a6-9b0d-f448627d7148
{ "InvoiceId": "1", "Price": "10.00", "Product": "Steering Wheel", "Quantity": "5" }
key - invoiceitem::bf9d3256-9c8a-4378-877d-2a563b163d45
{ "InvoiceId": "1", "Price": "20.00", "Product": "Tire", "Quantity": "2" }Posts tagged with 'json'
This is a repost that originally appeared on the Couchbase Blog: JSON Data Modeling for RDBMS Users.
JSON data modeling is a vital part of using a document database like Couchbase. Beyond understanding the basics of JSON, there are two key approaches to modeling relationships between data that will be covered in this blog post.
The examples in this post will build on the invoices example that I showed in CSV tooling for migrating to Couchbase from Relational.
Imported Data Refresher
In the previous example, I started with two tables from a relational database: Invoices and InvoicesItems. Each invoice item belongs to an invoice, which is done with a foreign key in a relational database.
I did a very straightforward (naive) import of this data into Couchbase. Each row became a document in a "staging" bucket.

Next, we must decide if that JSON data modeling design is appropriate or not (I don’t think it is, as if the bucket being called "staging" didn’t already give that away).
Two Approaches to JSON data modeling of relationships
With a relational database, there is really only one approach: normalize your data. This means separate tables with foreign keys linking the data together.
With a document database, there are two approaches. You can keep the data normalized or you can denormalize data by nesting it into its parent document.
Normalized (separate documents)
An example of the end state of the normalized approach represents a single invoice spread over multiple documents:
This lines up with the direct CSV import. The InvoiceId field in each invoiceitem document is similar to the idea of a foreign key, but note that Couchbase (and distributed document databases in general) do not enforce this relationship in the same way that relational databases do. This is a trade-off made to satisfy the flexibility, scalability, and performance needs of a distributed system.
Note that in this example, the "child" documents point to the parent via InvoiceId. But it could also be the other way around: the "parent" document could contain an array of the keys of each "child" document.
Denormalized (nested)
The end state of the nested approach would involve just a single document to represent an invoice.
key - invoice::1
{
"BillTo": "Lynn Hess",
"InvoiceDate": "2018-01-15 00:00:00.000",
"InvoiceNum": "ABC123",
"ShipTo": "Herman Trisler, 4189 Oak Drive",
"Items": [
{ "Price": "1000.00", "Product": "Brake Pad", "Quantity": "24" },
{ "Price": "10.00", "Product": "Steering Wheel", "Quantity": "5" },
{ "Price": "20.00", "Product": "Tire", "Quantity": "2" }
]
}Note that "InvoiceId" is no longer present in the objects in the Items array. This data is no longer foreign—it’s now domestic—so that field is not necessary anymore.
JSON Data Modeling Rules of Thumb
You may already be thinking that the second option is a natural fit in this case. An invoice in this system is a natural aggregate-root. However, it is not always straightforward and obvious when and how to choose between these two approaches in your application.
Here are some rules of thumb for when to choose each model:
| If … | Then consider… |
|---|---|
|
Relationship is 1-to-1 or 1-to-many |
Nested objects |
|
Relationship is many-to-1 or many-to-many |
Separate documents |
|
Data reads are mostly parent fields |
Separate document |
|
Data reads are mostly parent + child fields |
Nested objects |
|
Data reads are mostly parent or child (not both) |
Separate documents |
|
Data writes are mostly parent and child (both) |
Nested objects |
Modeling example
To explore this deeper, let’s make some assumptions about the invoice system we’re building.
-
A user usually views the entire invoice (including the invoice items)
-
When a user creates an invoice (or makes changes), they are updating both the "root" fields and the "items" together
-
There are some queries (but not many) in the system that only care about the invoice root data and ignore the "items" fields
Then, based on that knowledge, we know that:
-
The relationship is 1-to-many (a single invoice has many items)
-
Data reads are mostly parent + child fields together
Therefore, "nested objects" seems like the right design.
Please remember that these are not hard and fast rules that will always apply. They are simply guidelines to help you get started. The only "best practice" is to use your own knowledge and experience.
Transforming staging data with N1QL
Now that we’ve done some JSON Data Modeling exercises, it’s time to transform the data in the staging bucket from separate documents that came directly from the relational database to the nested object design.
There are many approaches to this, but I’m going to keep it very simple and use Couchbase’s powerful N1QL language to run SQL queries on JSON data.
Preparing the data
First, create a "operation" bucket. I’m going to transform data and move it to from the "staging" bucket (containing the direct CSV import) to the "operation" bucket.
Next, I’m going to mark the 'root' documents with a "type" field. This is a way to mark documents as being of a certain type, and will come in handy later.
UPDATE staging
SET type = 'invoice'
WHERE InvoiceNum IS NOT MISSING;I know that the root documents have a field called "InvoiceNum" and that the items do not have this field. So this is a safe way to differentiate.
Next, I need to modify the items. They previously had a foreign key that was just a number. Now those values should be updated to point to the new document key.
UPDATE staging s
SET s.InvoiceId = 'invoice::' || s.InvoiceId;This is just prepending "invoice::" to the value. Note that the root documents don’t have an InvoiceId field, so they will be unaffected by this query.
After this, I need to create an index on that field.
Preparing an index
CREATE INDEX ix_invoiceid ON staging(InvoiceId);This index will be necessary for the transformational join coming up next.
Now, before making this data operational, let’s run a SELECT to get a preview and make sure the data is going to join together how we expect. Use N1QL’s NEST operation:
SELECT i.*, t AS Items
FROM staging AS i
NEST staging AS t ON KEY t.InvoiceId FOR i
WHERE i.type = 'invoice';The result of this query should be three total root invoice documents.
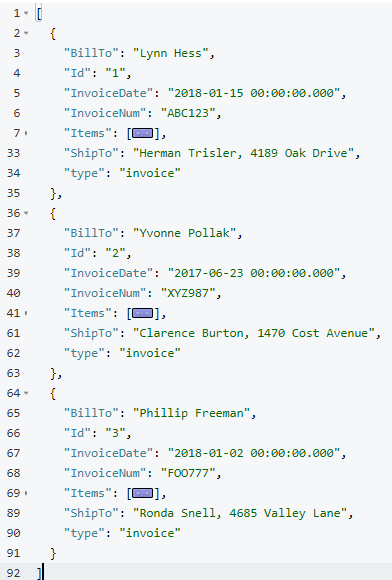
The invoice items should now be nested into an "Items" array within their parent invoice (I collapsed them in the above screenshot for the sake of brevity).
Moving the data out of staging
Once you’ve verified this looks correct, the data can be moved over to the "operation" bucket using an INSERT command, which will just be a slight variation on the above SELECT command.
INSERT INTO operation (KEY k, VALUE v)
SELECT META(i).id AS k, { i.BillTo, i.InvoiceDate, i.InvoiceNum, "Items": t } AS v
FROM staging i
NEST staging t ON KEY t.InvoiceId FOR i
where i.type = 'invoice';If you’re new to N1QL, there’s a couple things to point out here:
-
INSERTwill always useKEYandVALUE. You don’t list all the fields in this clause, like you would in a relational database. -
META(i).idis a way of accessing a document’s key -
The literal JSON syntax being SELECTed AS v is a way to specify which fields you want to move over. Wildcards could be used here.
-
NESTis a type of join that will nest the data into an array instead of at the root level. -
FOR ispecifies the left hand side of theON KEYjoin. This syntax is probably the most non-standard portion of N1QL, but the next major release of Couchbase Server will include "ANSI JOIN" functionality that will be a lot more natural to read and write.
After running this query, you should have 3 total documents in your 'operation' bucket representing 3 invoices.
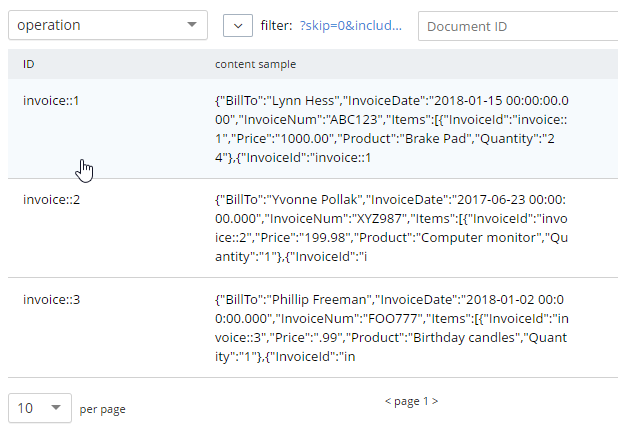
You can delete/flush the staging bucket since it now contains stale data. Or you can keep it around for more experimentation.
Summary
Migrating data straight over to Couchbase Server can be as easy as importing via CSV and transforming with a few lines of N1QL. Doing the actual modeling and making decisions requires the most time and thought. Once you decide how to model, N1QL gives you the flexibility to transform from flat, scattered relational data into an aggregate-oriented document model.
More resources:
-
Using Hackolade to collaborate on JSON data modeling.
-
Part of the SQL Server series discusses the same type of JSON data modeling decisions
-
How Couchbase Beats Oracle, if you’re considering moving some of your data away from Oracle
-
Moving from Relational to NoSQL: How to Get Started white paper.
Feel free to contact me if you have any questions or need help. I’m @mgroves on Twitter. You can also ask questions on the Couchbase Forums. There are N1QL experts there who are very responsive and can help you write the N1QL to accommodate your JSON data modeling.
This is a repost that originally appeared on the Couchbase Blog: XML to JSON conversion with Json.NET.
XML data can be converted to JSON, which can be loaded into Couchbase Server (Couchbase Server 5.0 beta now available). Depending on the source of the data, you might be able to use a tool like Talend. But you may also want to write a simple C# .NET application with Newtonsoft’s Json.NET to do it.
XML data
For the purposes of this tutorial, I’m going to use a very simple XML example. If your XML is more complex (multiple attributes, for instance), then your approach will also have to be more complex. (Json.NET can handle all XML to Json conversions, but it follows a specific set of conversion rules). Here’s a sample piece of data:
var xml = @"
<Invoice>
<Timestamp>1/1/2017 00:01</Timestamp>
<CustNumber>12345</CustNumber>
<AcctNumber>54321</AcctNumber>
</Invoice>";Notice that I’ve got this XML as a hardcoded string in C#. In a real-life situation, you would likely be pulling XML from a database, a REST API, XML files, etc.
Once you have the raw XML, you can create an XmlDocument object (XmlDocument lives in the System.Xml namespace).
XmlDocument doc = new XmlDocument();
doc.LoadXml(xml);Conversion with Json.NET
Once you have an XmlDocument object, you can use Json.NET to convert that object into a Json representation.
var json = JsonConvert.SerializeXmlNode(doc, Formatting.None, true);In this example, I’m asking Json.NET to serialize an XML node:
-
I used
Formatting.None. If I wanted to display the actual Json, it might be better to useFormatting.Indented -
The last
truespecifies that I want to omit the root object. In the XML above, you can think of<Invoice></Invoice>as the root object. I just want the values of the Invoice object. If I didn’t omit the root node, the resultant Json would look like:{"Invoice":{"Timestamp":"1/1/2017 00:01","CustNumber":"12345","AcctNumber":"54321"}}
Saving the Json result
Finally, let’s put the Json into Couchbase. The easiest way to do this would be to again call on JsonConvert to deserialize the Json into a C# object. That object would then be used with Couchbase’s bucket.Insert(…) method.
object transactObject1 = JsonConvert.DeserializeObject(json);
bucket.Insert(Guid.NewGuid().ToString(), transactObject1);With this method, the Json would be stored in Couchbase like so:
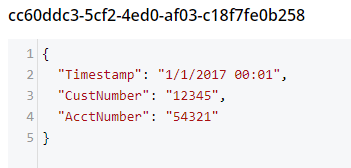
That might be fine, but often times you’re going to want more control of the format. With Json.NET, we can serialize to a given class, instead of just object. Let’s create an Invoice class like so:
public class Invoice
{
public DateTime Timestamp { get; set; }
public string CustNumber { get; set; }
public int AcctNumber { get; set; }
}Notice that there is some type information now. The Timestamp is a DateTime and the AcctNumber is an int. The conversion will still work, but the result will be different, according to Json.NET’s conversion rules. (Also check out the full Json.NET documentation if you aren’t familiar with it already).
Invoice transactObject2 = JsonConvert.DeserializeObject<Invoice>(json);
bucket.Insert(Guid.NewGuid().ToString(), transactObject2);The result of that insert will look like:
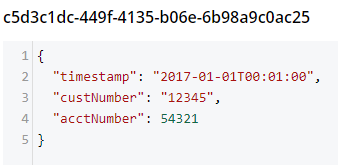
-
Notice that the timestamp field is different: it’s stored in a more standardized way.
-
The acctNumber field value is not in quotes, indicating that it’s being stored as a number.
-
Finally, notice that the field names are different. This is due to the way Json.NET names Json fields by default. You can specify different names by using the
JsonPropertyattribute.
That’s it
One more minor thing to point out: I used Guid.NewGuid().ToString() to create arbitrary keys for the documents. If you have value(s) in the XML data that you want to use for a key, you could/should use those value(s) instead.
This blog post was inspired by an email conversation with a Couchbase user. If you have any suggestions on tools, tips, or tricks to make this process easier, please let me know. Or, contact me if there’s something you’d like to see me blog about! You can email me or contact me @mgroves on Twitter.
This is a repost that originally appeared on the Couchbase Blog: SQL to JSON Data Modeling with Hackolade.
SQL to JSON data modeling is something I touched on in the first part of my "Moving from SQL Server to Couchbase" series. Since that blog post, some new tooling has come to my attention from Hackolade, who have recently added first-class Couchbase support to their tool.
In this post, I’m going to review the very simple modeling exercise I did by hand, and show how IntegrIT’s Hackolade can help.
I’m using the same SQL schema that I used in the previous blog post series; you can find it on GitHub (in the SQLServerDataAccess/Scripts folder).
Review: SQL to JSON data modeling
First, let’s review, the main way to represent relations in a relational database is via a key/foreign key relationship between tables.
When looking at modeling in JSON, there are two main ways to represent relationships:
-
Referential - Concepts are given their own documents, but reference other document(s) using document keys.
-
Denormalization - Instead of splitting data between documents using keys, group the concepts into a single document.
I started with a relational model of shopping carts and social media users.
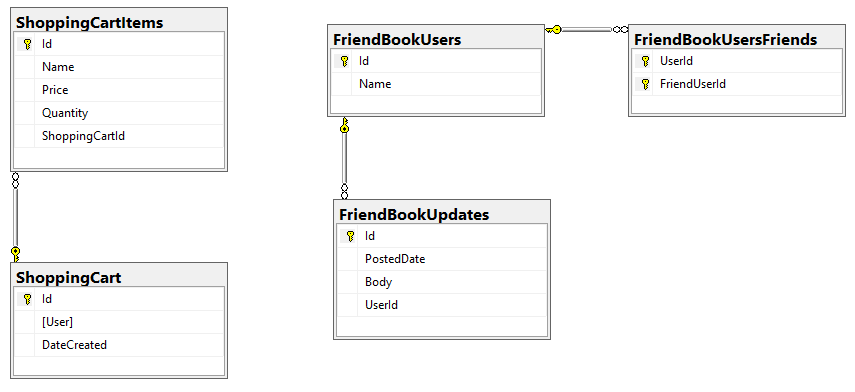
In my example, I said that a Shopping Cart - to - Shopping Cart Items relationship in a relational database would probably be better represented in JSON by a single Shopping Cart document (which contains Items). This is the "denormalization" path. Then, I suggested that a Social Media User - to - Social Media User Update relationship would be best represented in JSON with a referential relationship: updates live in their own documents, separate from the user.
This was an entirely manual process. For that simple example, it was not difficult. But with larger models, it would be helpful to have some tooling to assist in the SQL to JSON data modeling. It won’t be completely automatic: there’s still some art to it, but the tooling can do a lot of the work for us.
Starting with a SQL Server DDL
This next part assumes you’ve already run the SQL scripts to create the 5 tables: ShoppingCartItems, ShoppingCart, FriendBookUsers, FriendBookUpdates, and FriendBookUsersFriends. (Feel free to try this on your own databases, of course).
The first step is to create a DDL script of your schema. You can do this with SQL Server Management Studio.
First, right click on the database you want. Then, go to "Tasks" then "Generate Scripts". Next, you will see a wizard. You can pretty much just click "Next" on each step, but if you’ve never done this before you may want to read the instructions of each step so you understand what’s going on.
Finally, you will have a SQL file generated at the path you specified.
This will be a text file with a series of CREATE and ALTER statements in it (at least). Here’s a brief excerpt of what I created (you can find the full version on Github).
CREATE TABLE [dbo].[FriendBookUpdates](
[Id] [uniqueidentifier] NOT NULL,
[PostedDate] [datetime] NOT NULL,
[Body] [nvarchar](256) NOT NULL,
[UserId] [uniqueidentifier] NOT NULL,
CONSTRAINT [PK_FriendBookUpdates] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
-- etc...By the way, this should also work with SQL Azure databases.
Note: Hackolade works with other types of DDLs too, not just SQL Server, but also Oracle and MySQL.
Enter Hackolade
This next part assumes that you have downloaded and installed Hackolade. This feature is only available on the Professional edition of Hackolade, but there is a 30-day free trial available.
Once you have a DDL file created, you can open Hackolade.
In Hackolade, you will be creating/editing models that correspond to JSON models: Couchbase (of course) as well as DynamoDB and MongoDB. For this example, I’m going to create a new Couchbase model.
At this point, you have a brand new model that contains a "New Bucket". You can use Hackolade as a designing tool to visually represent the kinds of documents you are going to put in the bucket, the relationships to other documents, and so on.
We already have a relational model and a SQL Server DDL file, so let’s see what Hackolade can do with it.
Reverse engineer SQL to JSON data modeling
In Hackolade, go to Tools → Reverse Engineer → Data Definition Language file. You will be prompted to select a database type and a DDL file location. I’ll select "MS SQL Server" and the "script.sql" file from earlier. Finally, I’ll hit "Ok" to let Hackolade do its magic.

Hackolade will process the 5 tables into 5 different kinds of documents. So, what you end up with is very much like a literal translation.
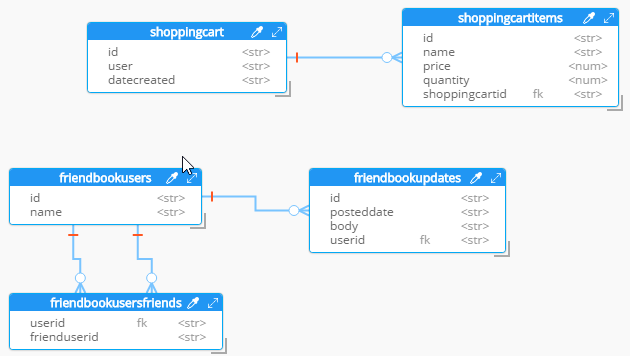
This diagram gives you a view of your model. But now you can think of it as a canvas to construct your ultimate JSON model. Hackolade gives you some tools to help.
Denormalization
For instance, Hackolade can make suggestions about denormalization when doing SQL to JSON data modeling. Go to Tools→Suggest denormalization. You’ll see a list of document kinds in "Table selection". Try selecting "shoppingcart" and "shoppingcartitems". Then, in the "Parameters" section, choose "Array in parent".
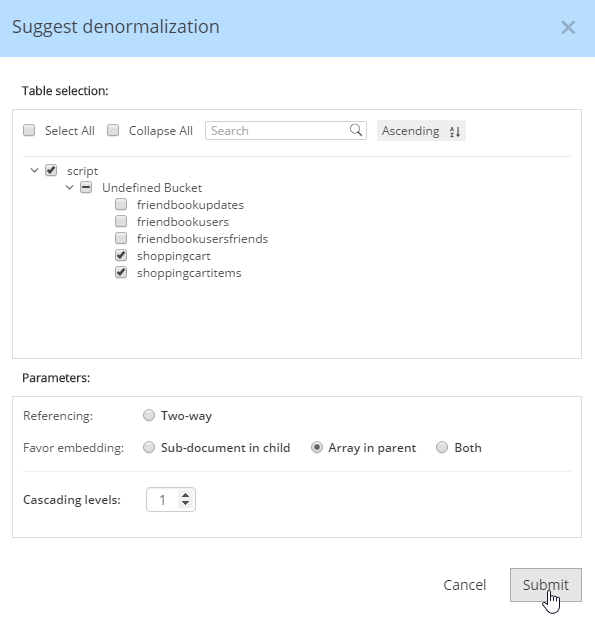
After you do this, you will see that the diagram looks different. Now, the items are embedded into an array in shoppingcart, and there are dashed lines going to shoppingcartitems. At this point, we can remove shoppingcartitems from the model (in some cases you may want to leave it, that’s why Hackolade doesn’t remove it automatically when doing SQL to JSON data modeling).
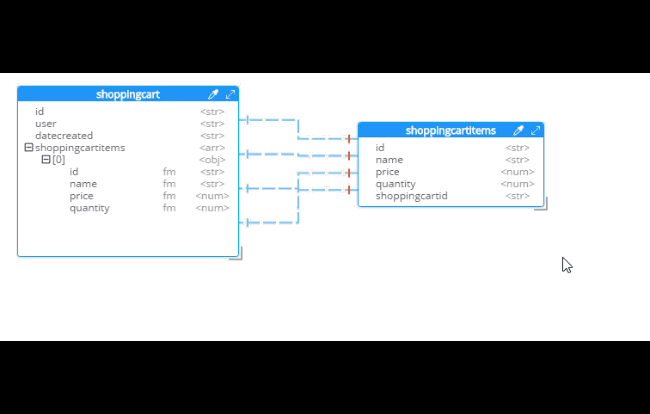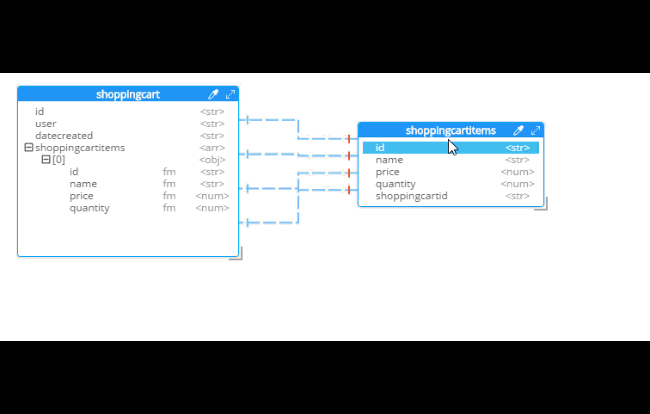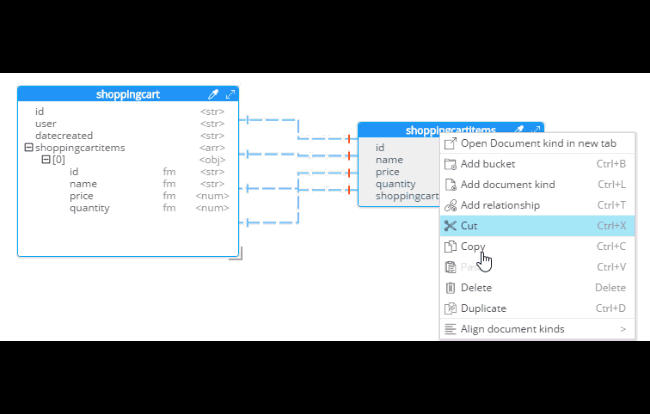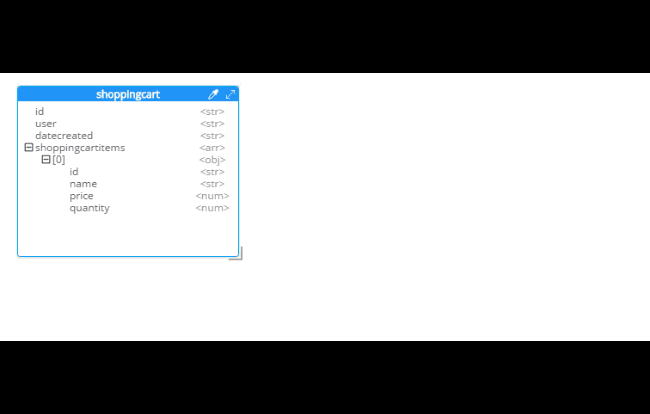
Notice that there are other options here too:
-
Embedding Array in parent - This is what was demonstrated above.
-
Embedding Sub-document in child - If you want to model the opposite way (e.g. store the shopping cart within the shopping cart item).
-
Embedding Both - Both array in parent and sub-document approach.
-
Two-way referencing - Represent a many-to-many relationship. In relational tables, this is typically done with a "junction table" or "mapping table"
Also note cascading. This is to prevent circular referencing where there can be a parent, child, grandchild, and so on. You select how far you want to cascade.
More cleanup
There are a couple of other things that I can do to clean up this model.
-
Add a 'type' field. In Couchbase, we might need to distinguish shoppingcart documents from other documents. One way to do this is to add a "discriminator" field, usually called 'type' (but you can call it whatever you like). I can give it a "default" value in Hackolade of "shoppingcart".
-
Remove the 'id' field from the embedded array. The SQL table needed this field for a foreign key relationship. Since it’s all embedded into a single document, we no longer need this field.
-
Change the array name to 'items'. Again, since a shopping cart is now consolidated into a single document, we don’t need to call it 'shoppingcartitems'. Just 'items' will do fine.

Output
A model like this can be a living document that your team works on. Hackolade models are themselves stored as JSON documents. You can share with team members, check them into source control, and so on.
You can also use Hackolade to generate static documentation about the model. This documentation can then be used to guide the development and architecture of your application.
Go to File → Generate Documentation → HTML/PDF. You can choose what components to include in your documentation.
Summary
Hackolade is a NoSQL modeling tool created by the IntegrIT company. It’s useful not only in building models from scratch, but also in reverse engineering for SQL to JSON data modeling. There are many other features about Hackolade that I didn’t cover in this post. I encourage you to download a free trial of Hackolade today. You can also find Hackolade on Twitter @hackolade.
If you have questions about Couchbase Server, please ask away in the Couchbase Forums. Also check out the Couchbase Developer Portal for more information on Couchbase for developers. Always feel free to contact me on Twitter @mgroves.
My job as a developer evangelist for Couchbase means than I work much less with SQL Server than I used to. However, it doesn't mean I don't keep up with it.
In fact, inspired by Couchbase, I decided to try out using SQL Server as a sort of document data store. SQL Server 2016 introduced some interesting new features that make this kinda possible: JSON_VALUE, JSON_QUERY, and JSON_MODIFY.
I set up a "document" table, which is two fields: a guid and an nvarchar(max). This is kinda like a Couchbase bucket: a key and a JSON document to go with it.
I put fairly complex hierarchical documents in these fields, something like:
I say "fairly complex", because representing this in a standard normalized fashion would require at least two tables, foreign keys, constraints, and then data migration and schema migration as the model evolves.
Now, suppose I want to execute a query and find all the document that are "Show=true". With Couchbase and N1QL, I would just use something like "SELECT * FROM `bucket` WHERE show = true".
With SQL Server, there's a little more work. "SELECT t.key, t.doc FROM [table] t WHERE JSON_VALUE(t.SpeakingInfo,'$.Show') = 'true'". Notice that JSON_VALUE is being applied to a text field, and a JSON path is used within JSON_VALUE to get a specific value from within that JSON object.
For this simple project I'm doing, that's all I need. No idea yet what kind of performance level I can expect from JSON_VALUE and more complex JSON paths.
But, this is definitely an example of the kinds of database convergence I've been telling people about. The separations between NoSQL and SQL are becoming less strict, at least in terms of data modeling and querying.
You need to be using SQL Server 2016 or SQL Server Azure to take advantage of the JSON_* functions.
Hi! This is one of the most popular posts on my blog, just wanted to say "thank you!" for stopping by! Also, sorry about the whole ASP Classic thing. But good luck! If you're into podcasts, check out The Cross Cutting Concerns Podcast, with interviews about interesting and fun technology.
I've recently had to write some ASP Classic. Don't worry, it's not like I'm writing new features, just integrating with old ones. So, since this is an ancient technology, some of this may be old news to you. But much of it was new to me, and I'm a developer with some years of ASP Classic experience.
Most of the stuff I had to do was pretty minor, but one major thing I found interesting was that I had a need to make an HTTP request in ASP classic. This turns out to be not so bad.
The trickiest part was figuring out that I had to explicitly specify the content type, since it apparently doesn't set a default.
So, yay! But also, uh oh. Now I have a response, but it's in Json. How the heck do I deal with that in ASP Classic? I was already worried about having to create an XML endpoint or finding some hacky JSON parser written in VBScript. But I took a deep breath and Googled it first. I was pleasantly shocked with what Stack Overflow told me about parsing Json in ASP. Did you know that ASP Classic is typically associated with VBScript, but actually can support other languages, like JScript and PerlScript? JScript is Microsoft's implementation of ECMAScript (commonly referred to as JavaScript), which they made available server-side via ASP long before you had a crush on Node.js. (Yeah I'm trolling a bit, but give me a break: as I write this, I've been layed up with the flu watching a House, M.D. marathon on Netflix, so I'm feeling a bit snarky).
ANYWAY
If we can run JScript and VBScript with the same ASP Classic page, then guess what, we can use Douglas Crockford's JSON library. It's so perfect and simple, and I wish I came up with it on my own.
That's about 100 times more elegant of a solution than I even expected when I started on this code.
