Posts tagged with 'F'
I'm starting up a series of brief, informal, biographical blog posts about some of the most important people in the history of computer called "Brief Bios".
I've made a list, and I'm just going to start chronologically. One of the challenges with biographies in historical computing is that computing, especially its early history, is inextricably tied to mathematics. This means that I could go all the way back to the very roots of mathematics, but I won't. I will instead be drawing an arbitrary line (this whole series will contain a lot of arbitration, in fact). I'll be starting at Wikipedia and branching out from there, based on what catches my interest.
So, just keep in mind that this is a blog, and therefore a series of relatively short, informal posts. Think of this series as a starting place for learning more about these people; each of their lives and the work of lives of those they've influenced could easily fill an entire library (and for some of them, that's literally the case). It's entirely certain that my blog posts will contain much that is apocraphal, or at least wildly inaccurate. I welcome your corrections and omissions in the comment section.
Blaise Pascal
Blaise Pascal, born in 1623, was a philosopher, mathematician, and physicist. But his greatest contibution to computing was spurred by taxes. Pascal may have been the first person to ever obtain a software patent for his calculating machine, the Pascaline, invented in 1642 and shown to the public in 1645. In 1649, King Louis XIV granted a royal privilege to Pascal, which gave him exclusivity to design and manufacture calculating machines. I'd wager that his wealthy father, Étienne Pascal, who was a lawyer and French aristocrat helped to arrange this, before he died in 1651. Certainly Étienne influenced the invention of the machine in the first place, since he was also a tax official (his father being Martin Pascal, a treasurer of France). Since Étienne took it upon himself to be his children's formal educator, I imagine the Pascal hallways filled with the pitter-patter of decimal points.

The Pascaline was not a commercial success. After 50 prototypes, he built around 20 more production machines. As useful as a mechanical calculator might have been for calculating taxes, the Pascaline was seen more as a status symbol (a concept that's not completely foreign to modern consumers who pay twice as much for comperable hardware with a certain logo on it). Nine machines are known to still remain today; the only one in the US is in the IBM archives (but it says it's a replica, so why does that count?) which I guess is in New York somewhere? I would like to check out that IBM attic someday.
Here's a video about how the Pascalines work. The machine consists of inputs (dials) and outputs (windows). Each input is kinda like a rotary phone, and is used to enter digits. The results of the calculation are then displayed in the digit windows, which kinda look like single-digit odometers. "Carry the one" operations are handled by a mechical arm that spans internally between dials. Subtraction is also possible with nines' compliments. You can build a Pascaline with Lego. I believe it's safe to say that these devices are not Turing-complete, and therefore not programmable computers, since you cannot have any conditional branching and you cannot arbitrarily change memory locations. It's essentially a one-way counter that can count by 1s,10s,100s,etc.
Lots of things are named after Pascal. The Pascal programming language, developed by Niklaus Wirth, is one that many programmers have probably at least heard of.
In his final years, Pascal had all sorts of nasty health problems and illness, including a brain lesion. In 1662, his last words were "May God never abandon me", and he's buried in Saint-Étienne-du-Mont - a Church bearing his father's namesake.

The plaque says, approximately: "The body of Blaise Pascal who died August 19, 1662 in the parish of Saint Étienne Du Mont was buried near this pillar. R.I.P."
I took a long break from ORMs in my career: about 4 years. I was working on a reporting product, and an ORM is just the wrong tool for that. Before that, I worked with ORMs here and there: NHibernate and another ORM I don't even want to mention by name for fear of being associated with it in public. For some of my own projects like the next version of EZRep and this very blog site, I've switched to a so-called micro-ORM, specifically Dapper.
Now that I'm back to consulting, I'm back into the ORM game. This time, it's Entity Framework. Early in this project (that uses EF), I've been experiencing quite a bit of frustration. It seems like I'm swimming upstream while jumping through hoops to accomplish really simple things that wouldn't take nearly as much work in Dapper. Maybe this is just me getting back into the habit, but it's also got me thinking: why do I really need a "full" ORM anymore? Abstraction and indirection are important tools, but perhaps full ORMs aren't the least leaky abstraction anymore in many cases?
Yes, a full ORM is sometimes RTRJ. However, I think micro ORMs (Dapper, PetaPoco, Massive) and document databases (Raven, Couch, Mongo) have taken a big bite out of the pool of possible use cases, and that a lot of full ORM and/or RDBMS usage in projects is really used not because it's the best tool, but because of the sheer momentum of the status quo. Imagine a snapshot of a Venn diagram taken 5 or 10 years ago compared to one I made up to represent a snapshot of today.
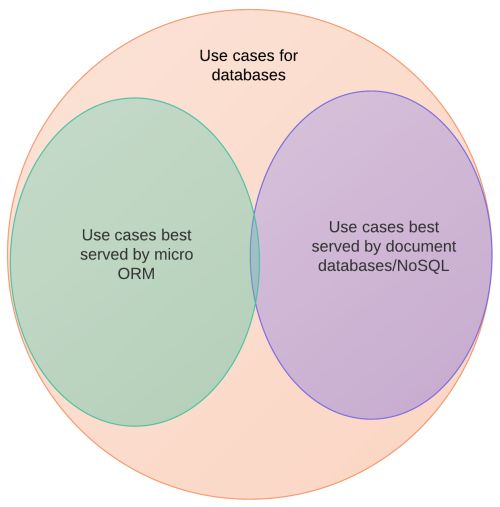
There might be missing bubbles like "RDBMS + no ORM" or "Json string in text file", and the exact proportions are open to interpretation. But the point I'm trying to make is this: the number of use cases that are best served by RDBMS + full ORM is shrinking, and will continue to shrink.
May 13th is .NET Day at manning.com. My book (AOP in .NET) is featured as part of this Deal of the Day.
The offer also applies to:
- C# in Depth, Third Edition by Jon Skeet
- Fast ASP.NET Websites by Dean Alan Hume
- Windows Store App Development by Pete Brown
- HTML5 for .NET Developers by Jim Jackson and Ian Gilman
- Metaprogramming in .NET by Kevin Hazzard and Jason Bock
- Dependency Injection in .NET by Mark Seemann
- ASP.NET 4.0 in Practice by Daniele Bochicchio, Stefano Mostarda, and Marco De Sanctis
- F# Deep Dives by Tomas Petricek and Phillip Trelford
- And C++ Concurrency in Action by Anthony Williams
The deal will stay active for about 48 hours. (They let it run a little longer than a day to account for time zones). So get yourself some books!
Use promo code dotd051314au.
The Boise .NET User Group was kind enough to invite me to be a presenter. Boise is a bit too far away for me to make it there on a weekday on a small budget, but they were accomodating enough to allow me to present remotely. There were a couple minor technical issues, but mostly it went well. Even though I've done this presentation a lot, Brian cajoled me into talking about INotifyPropertyChanged, which is something I've only done once before during this talk (usually I'm constrained for time, or the group isn't interested in the MVVM pattern).
Brian Lagunas even made a recording of the presentation. The recording started a minute or so late, and it ending a couple minutes too early (the internet in the Boise location went down), but most of it is was recorded with Microsoft Live Meeting (not my favorite remote collaboration tool, but it was adequate). And now, it's on YouTube:
Slides and code are available in the AOP For You and Me GitHub repository.
Managing database migrations is an important part of a project. Everyone on the team needs to be on the same page when it comes to the database, while still having the ability to make database changes when necessary.
I've used a variety of tools to do this on various projects, but one tool that I especially like is Fluent Migrator.
The idea with Fluent Migrator is to create a series of classes that create and modify the database schema (and data). Each class represents a single "migration" (in the sense that you are "migrating" from an empty database to a database with something in it). Here's an example of a migration that I might create if I were creating a table to store user information:
Several things to note:
Fluent syntax. This just means that you can chain stuff together in a natural and fluent way (see NDecision, Fluent NHibernate, Fluent Validation, etc for other examples). This was kinda a "trend" for a while in C# projects, but it does make sense in a number of contexts. The goal is to make the API discoverable and easy to use and also to make the code easier to read. Note that there are some sensible defaults when you create columns, but it never hurts to be explicit.
Migration attribute and Migration base class. This attribute and base class needs to be on each migration class. The number in the attribute determines the order in which the migrations will be executed (we only have 1 so far, but the next one would be 2, for instance).
Up and Down. Override the "Up" method to put in the code that will create/alter the database. Override the "Down" method to put in the code that will revert the changes made in the "Up" method. In some cases, it may not make sense to create a "Down".
Okay, let's say I create that migration, execute it (more on how to execute it later) against a database, write some code that uses that table, and check everything in. The next day, I learn that I need to create an optional "url" field for users. To do that, I'll create another migration class (I'm not editing the existing migration).
These migrations get compiled into a plain DLL, so to actually execute them against a database, you'll need some sort of migration runner. I've been using the command line runner, but there are runners for NAnt, MSBuild, and Rake available too if you use any of those tools on your build server to automatically deploy the database migrations alongside your application.
My next step usually involves creating some convenience batch files to use the command line migration runner. You can use these locally while you develop, or possibly call them as part of your build process. Here's an example of a set of batch files that I use to "Up" my local database to run all the latest migrations and one to "Down" my migration back a number of steps (both of these operations are very common while developing).
I put these in the project, but I always have them deploy to the bin folder (where the compiled migrations are). You could do it vice versa if you want.
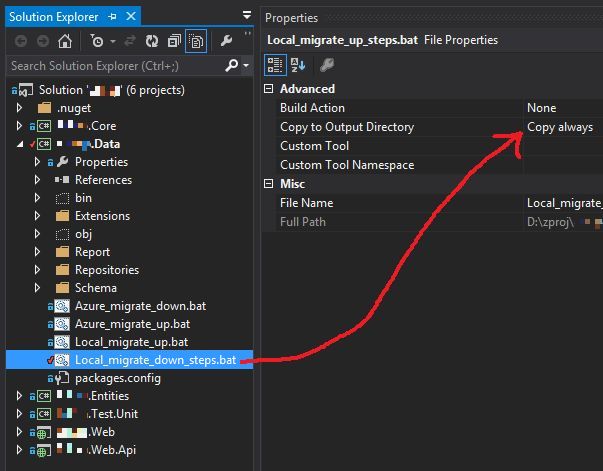
So that's it. Works against SQL 2012 and SQL Azure, in case you were wondering.
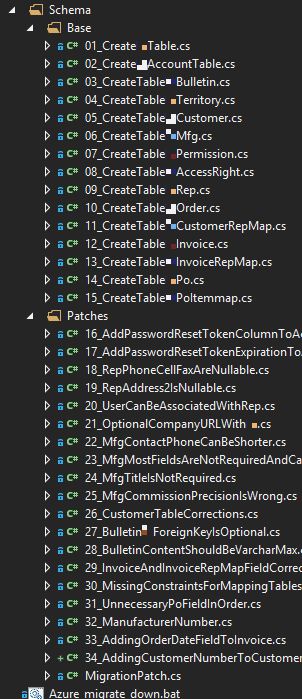
One other thing I do for the sake of organization is that I name all my migration files like NN_MigrationName. When I look at the list of files, I'll see them in migration order. Here's a screenshot from a real project of mine: