// SqlServerFrom.cs
public IEnumerable<dynamic> QueryBulk(IDbConnection conn, SqlPipelineBase pipeline)
{
return conn.Query(pipeline.Query, buffered: false);
}
// SqlToCb.cs
foreach(var row in rows)
{
// ... snip ...
await collection.UpsertAsync(documentKey, row);
// ... snip ...
}Posts tagged with 'C'
It's the first ever C# Advent 2021 awards! Every year, you all put out such great stuff. Every post is the best!
But, I wanted to do something to recognize the best of the best: the standouts from the latest Advent that have performed above and beyond, and give everyone a chance to revist them and give the Advent one last "hurrah".
Some of these rewards are based on stats like Google Analytics and Reddit upvotes. Some of them are completely arbitrary. I hope you enjoy!
☝ Most Reddit Upvotes
I make sure all of the articles are submitted to /r/csharp and /r/dotnet (with permission of the respective admins). Here are the posts that got the most (combined) upvotes (as of January 5th, 2022):
1. Don't Do That, Do This: The .NET 6 Edition - Dave Brock killed it with over 300 upvotes
2. String Interpolation Trickery and Magic with C# 10 and .NET 6 - Brant Burnett bringing in around 150 votes
3. Using DateOnly and TimeOnly in .NET 6 to Simplify Your Code - from Christopher C. Johnson, grabbing around 100 votes
🖱 Most Clicks from the C# Advent Site
I put Google Analytics on the C# Advent site for the first time this year. This award will favor the earlier participants, of course. Here are the posts that have been most clicked on from the site.
1. Fastest way to enumerate a List<T> from Gérald Barré got 292 clicks from 272 users
2. The shortest quine in C# 9 and 10 from Martin Zikmund got 276 clicks from 259 users
3. Using C# and Auto ML in ML .NET to Predict Video Game Ratings got 242 clicks from 225 users
🤓 Matt's Favorite
Every post is great and appreciated, but these in particular stuck out to me as especially interesting, fun, and/or useful. Got favorites of your own? Leave a comment below, tweet #csadvent, or write your own C# Advent Awards blog post!
1. Can You Teach C# as a First Language for Kids? - Excellent points made about the strengths and challenges, some great examples and ideas.
2. Fastest way to enumerate a List<T> - Straightforward topic, easy to understand, and introduced me to BenchmarkDotnet!
3. Parallel.ForEachAsync Deep Dive - Again, I was introduced to a tool that I wasn't aware of, and I can potentially make use of.
🐣 Best Newcomer
The best content from someone who has never been on the C# Advent before. The criteria is a combination of all the above.
1. Sarah Dutkiewicz - I can't believe it's Sarah's first time, but she killed it. She claimed day 1, which may be the most challenging day. AND she filled in for someone who dropped out, just two days later. Well done!
2. Matthew MacDonald - My favorite entry this year is from a first-timer.
3. Alvin Ashcraft - Another author who I can't believe is a first-timer! Check out Calling the Microsoft Graph API from WinUI
👴 Best Veteran
Same as above, except for those who have posted to the C# Advent before.
1. Brant Burnett - One of the first to sign up back in 2017, and he has delivered every year since. This year his post was especially popular: String Interpolation Trickery and Magic with C# 10 and .NET 6
2. Ed Charbeneau - Another great post this year. Ed is one of the most enthusiatic participants, and he always creates a great entry: Accessibility Test–Driven Blazor Components
3. Baskar Rao - He is a workhorse when it comes to the C# Advent. A unique topic this year: A Quick Peek of Accessibility Insights and Automating Desktop Applications
Honorable Mention to Roman Stoffel, just because I love the illustrations in Automated Tests Advice, C# Edition
Thank you to everyone who participated! I've already started planning enhancements for next year. Be sure to watch mgroves on Twitter, the C# Advent site, and this very blog for announcements when the calendar gets toward the last third.
Thank you Smashing Magazine for featuring the C# Advent in your Advent Calendars For Web Designers And Developers (December 2021 Edition) round-up.
Thank you Sergey Tihon for the inspiration.
A special extra thanks to Calvin Allen, who does a lot of behind-the-scenes work on C# Advent (including the domain name, LinkedIn, the new CsAdvent twitter account, testing, and much more) AND writes an Advent entry AND deserves accolades for all of it!
Welcome to day 16 of the 2021 C# Advent! Make sure to check out all the other great Advent items that have been opened so far!
I have been working on an experimental tool called SqlServerToCouchbase. The goal is to help people automate their relational data moving and refactoring into a Couchbase JSON database as much as possible.
It is a .NET library that you can use (in, for example, a console project). It maps a relational concept like "table" to a NoSQL concept of "collection" (among other things). Couchbase is particularly suited to this, because Couchbase also supports SQL as a querying language (with JOINs / ACID / INSERT / UPDATE / etc), and has supported SQL for many years. If that sounds interesting to you, I’d love for you to leave your feedback, criticisms, suggestions, and even pull requests on GitHub.
What I want to focus on today, however, are three great .NET libraries that I used to help build SqlServerToCouchbase. Three wise gifts: SqlServer.Types (gold), Dynamitey (frankincense), and Humanizer (myrrh).
dotMorten.Microsoft.SqlServer.Types (Gold)
The gift of gold signified that the receiver was as important as a king.

SQL Server has many data types. Mapping these data types into C# types (and ultimately to JSON) is usually straightfoward.
-
varchar, nvarchar, text? string. -
int, float, decimal, money? number. -
bit? boolean. -
Even XML can become a string.
But what about the other types? Spatial types, mainly: Geography and geometry? That’s what Microsoft.SqlServer.Types is for: to provide C# types that can store propietary SQL Server data type values.
However, notice the "dotMorten" part of the library name? Unfortunately, the official Microsoft.SqlServer.Types library is not a .NET Standard library. So, Morten Nielsen created the dotMorten.Microsoft.SqlServer.Types library.
There’s a code example below, but you won’t see the library in action explicitly.
I use Dapper to query SQL Server data, store those results in C# dynamic objects, and then give those objects to the Couchbase .NET SDK (which ultimately serialized it to JSON).
That means that a row of SQL Server data, like this:
SELECT a.AddressID, a.SpatialLocation
FROM AdventureWorks2016.Person.Address a
WHERE a.AddressID = 1
Gets transformed into a Couchbase JSON document like this:
SELECT a.AddressID, a.SpatialLocation
FROM AdventureWorks2016.Person.Address a
WHERE a.AddressID = 1;[ {
"AddressID": 1,
"SpatialLocation": {
"HasM": false,
"HasZ": false,
"IsNull": false,
"Lat": 47.7869921906598,
"Long": -122.164644615406,
"M": null,
"STSrid": 4326,
"Z": null
}
} ]So, even if a SQL Server database is using one of these less common data types, SqlServerToCouchbase can still move it.
Dynamitey
The second gift is frankincense. This is an expensive incense fit for a holy king.

Another challenge of SqlServerToCouchbase is getting the value of the primary key. In Couchbase, a document key exists as a piece of "metadata" about the document. However, in SQL Server, a primary key consists of one (usually) or more (uncommon) fields in a table. These fields can have ANY name. Usually it’s something like "ID", "AddressID", "ADDRESS_ID", etc. But it can vary from table to table.
Once I know the names of the fields, I need to examine the dynamic object to get the values of those fields. This is where I use Dynamitey.
Dynamitey is a utility library that provides extensions to the DLR, including:
-
Easy Fast DLR based Reflection (what I’m using it for)
-
Clean syntax for using types from late bound libraries
-
Dynamic Currying
-
Manipulation of Tuples
And more.
Key names can be retrieved from SQL Server by querying INFORMATION_SCHEMA.KEY_COLUMN_USAGE. I can use those names to get the values like so:
// append key values together with :: delimeter
// for compound keys
var keys = await _config.GetPrimaryKeyNames(tableSchema, tableName, _dbFrom);
var newKey = string.Join("::", keys.Select(k => Dynamic.InvokeGet(row, k)));If a primary key is made up of one column and the row has a value of "1", then that becomes the document key in Couchbase. If a primary key is made up of multiple columns, with values of "123" and "456", that becomes a document key in Couchbase of "123::456".
If it weren’t for Dynamitey, I’d have to create C# classes for every table. And that greatly reduces the amount of automation.
Humanizer
The third gift is myrrh. Another expensive gift. This one is fit for a holy, but also human king.

Humanizer is a .NET library that manipulates string, dates, numbers, etc, for display to a human. There are many things it can do, but I use it for pluralization.
When making the transition from relational to Couchbase, one of the things you must consider is when to embed data into documents. For instance, in relational, you may have two tables (Person and EmailAddress) in order to support a situation where a person has more than 1 email addresses.
SELECT p.BusinessEntityID, p.FirstName, P.LastName
FROM AdventureWorks2016.Person.Person p
WHERE p.BusinessEntityID = 1
SELECT e.EmailAddress
FROM AdventureWorks2016.Person.EmailAddress e
WHERE e.BusinessEntityID = 1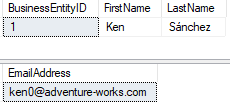
(In this example, there’s only 1 email address, but the model supports more).
In a document database like Couchbase, it’s often preferable (though not required) to embed those email addresses into an array in the person document. Something like:
{
"BusinessEntityID" : 1,
"FirstName" : "Ken",
"LastName" : "Sánchez",
"????" : [
{ "EmailAddress" : "[email protected]"}
]
}But what do I put into the "????" in that JSON? If I use the name of the table ("EmailAddress"), that implies that there’s only one. I would rather it be called "EmailAddresses". Hence, I use Humanizer to pluralize it:
spec.ArrayAppend(From.TableName.Pluralize(), docToEmbed.ContentAs<dynamic>(), true);So, now it becomes:
{
"BusinessEntityID" : 1,
"FirstName" : "Ken",
"LastName" : "Sánchez",
"EmailAddresses" : [
{ "EmailAddress" : "[email protected]"}
]
}Thanks for checking out these three libraries! I hope these will help you some day. Don’t forget to check out the rest of the 2021 C# Advent.
Short version:
The 2021 C# Advent is now open! If you've participated before, I suggest you visit https://csadvent.christmas to claim your spot right away!
Long version:
The C# Advent is an annual event, showcasing content (blog posts, videos, articles, podcast episodes, whatever!) from C# developers and enthusiasts, every day, from December 1st to December 25th.
Each day will feature two pieces of content. Each piece of content links back to the main C# Advent site, kinda like an old fashioned webring.
What do I have to do to participate?
Right now: just sign up. Go to https://csadvent.christmas, look for an open spot, and claim it. You'll receive an email with a special link. Click that link, fill out the form, and you're in! You do NOT need to tell me a title, topic, idea, or anything like that at this stage.
What do I do after I claim a spot?
Work on some content. It must be C# related and it must link back to https://csadvent.christmas, but otherwise, it can be whatever you'd like. Historically, it's mostly blog posts, but there's also been videos and podcast episodes. Any content that can be linked to is fine with me!
Do I give you the content to publish?
No! Publish it on your website, YouTube channel, podcast, whatever. That's the whole point: to help you get attention and noticed by the C# community.
When must I have it finished?
Technically, you don't need to have it done until the day that you claimed. I'd recommend that you get it done before then, because December is a busy holiday time for many of us. Just don't make it public until the day you signed up for.
What does "Advent" mean?
Advent is a season leading up to Christmas Day. Advent Calendars mark the days until Christmas. For children, the marking of each day might include a piece of candy or a small toy.
What are some good examples of C# Advent content?
ANY and ALL content that's related to C# is good in my book. The point is to promote the community, our love of C#, and to lift everyone up! However, if you're looking for some good examples to check out, here are a few that I really like:
- Combining Integration and UI Automation in C# from Hilary Weaver-Robb - the very first one happens to be one of the best
- The .NET Core Podcast: Noda Time with Jon Skeet - a podcast episode with one of the top C# names in the community
- Blazor Advent Calendar - a video about creating an Advent Calendar that is, itself, part of an Advent Calendar
But remember: you don't have to do anything flashy! If you care about C# and you've got something you want to share, I want you to claim a spot!
How long have you been doing this?
The first C# Advent calendar was in 2017.
You're out of open spots! I missed it!
Maybe not! December can be a hectic month, and sometimes people need to drop out. If you want to be on standby, contact me. Being on standby is one of the hardest jobs, since people may drop out with very little notice. But, if you are up to the task, I very much appreciate it, and I'm willing to accomodate or help you in any way I can.

For this year's C# Advent, I decided to finally implement an idea that I've been kicking around for a couple of years now. It's a parody of Baz Luhrmann's Everybody's Free (To Wear Sunscreen) track from 1997. The "lyrics" are from a Chicago Tribune column written by Mary Schmich, entitled "Advice, like youth, probably just wasted on the young". Much of the advice in the original song has stuck with me over the years, and it continues to be relevant and entertaining.
I thought that a version created just for developers, programmers, coders, engineers would be fun. I commissioned the help of voice actor Noah Jenkins (on Twitter @GeekyVoices) to bring a voice to my writing, and I laid his voice over a karaoke version of the song. (By the way, if you need voicework, I can highly recommend him!)
Please enjoy! Make sure to check out all the other great entries into this year's C# Advent. I look forward to doing it again next year.
Lyrics:
Coders, developers, software engineers, and programmers in the year of 2020
Write unit tests
If I could offer you only one tip for the future
Unit tests would be it
The long term benefits of unit tests have been proven by studies
Whereas the rest of my advice
Has no basis more reliable than my own
Meandering, flawed experience
I will dispense this advice...now.
Enjoy the power and beauty of your code
But, never mind
You'll look back on your code in 6 months and wonder who let you near a keyboard.
But trust me, this means you're improving.
Seeing your past code as flawed just means that you are learning.
You are not as bad a coder as you imagine.
Don't worry about the future
Or worry
But know that worrying is as effective as trying to write the next Facebook on a TRS-80.
The real troubles in your career are apt to be things that you never learned in college or boot camp.
The kind where your team decides to deploy to production on Friday at 5pm.
Do something everyday that challenges you.
Draw.
Don't judge other people harshly in code review.
Don't put up with people who harshly judge yours.
Write docs.
Don't waste time on jealousy.
Some days you're killing it, some days you aren't.
The race is long
And in the end, it's only with yourself.
Remember the compliments, put them in a special folder.
Forget YouTube comments.
If you succeed in doing this, tell me how
Keep your old code in an open source repository
Throw away your unused domain names.
Take days off.
Don't feel guilty if you don't know what you want to do with your career
The most interesting people I know aren't doing at 40 what they thought they wanted to do at 22.
And many of them say they still don't know what they're doing.
Be kind to your wrists
You'll miss them when they're gone
Maybe you'll start a company, maybe you won't
Maybe you'll get stock options and bonuses, maybe you won't.
Maybe you'll go into management.
Maybe you'll give up on computers completely and open a boutique when you turn 50
Whatever you do, don't congratulate yourself too much or berate yourself either
Your choices are at least partially chance, and so are everybody else's
Use your body
Use it on something manual and analog
Don't be afraid of stepping away from the computer, and what you might miss on Twitter
Honest labor will let your mind rest
Learn.
Even if your boss isn't going to pay for it
Read blog posts, even if you don't agree with them
Go to conferences, even if you spend more time in the hallway than the sessions
Education is not something you can ever finish.
DO NOT read the comments on Hacker News and Reddit, they will only make you feel terrible
(chorus)
Get to know your family
You never know when they'll be gone for good
Be nice to your siblings
They are your best link to your past
And the people most likely to stick with you in the future
Send a Snopes link if you must
But don't argue with their political views in public on Facebook
Understand that teammates come and go
But for the precious few you should hold on to
Work hard to bridge the gaps in geography and lifestyle
Because the older you get, the more you need the people that knew you when you were young
Work for a government agency once
But leave before it makes you grumpy
Work for a silicon valley startup once
But leave before it turns you into an insufferable hipster
Travel
Accept certain inalienable truths
Developers get distracted by newer frameworks
Bugs will always be around
You too will get old
And when you do, you'll fantasize that when you were young
New frameworks were always better
There weren't so many bugs
Certifications were important
And junior developers respected their seniors
Respect YOUR seniors
Don't expect anyone to hand you anything
Maybe you'll have stock options
Maybe you'll get V.C. funding
But you never know when either might run out
Don't be cocky about any once piece of technology
Or by the time you're 50, you'll be known as "that Windows Phone guy"
Be careful whose mentorship you seek
But be patient with anyone who supplies mentoring
Advice is a form of nostalgia
Dispensing it is a way of fishing the past from the garbage, wiping it off
Smoothing over the ugly parts and redeeming it for more than it's worth
But trust me on the unit tests
(chorus)
This year's Advent is going to be a little different that the Advents in 2019, 2018, and 2017.
This year, the C# Advent has its very own site!
Not only that, but the process is more automated this year. Gone are the days of me having to maintain an Excel spreadsheet.
Step 1:
Go to www.csadvent.christmas. Find an open spot in the Advent, and click to claim it. You will need to login with GitHub. There are two spots every day, for a total of 50 spots.
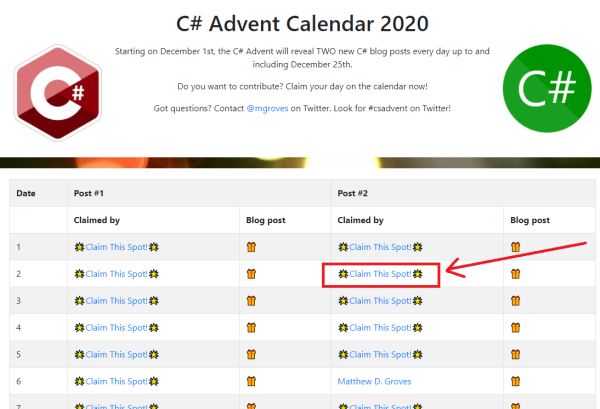
Step 2:
Fill out the request form. You'll need a name and email at least. You can also supply a URL for the link for your name (e.g. if people click "Matthew Groves", I want it to go to my Twitter). You can also add an optional comment. Only the Name and URL will appear publicly! Click submit.
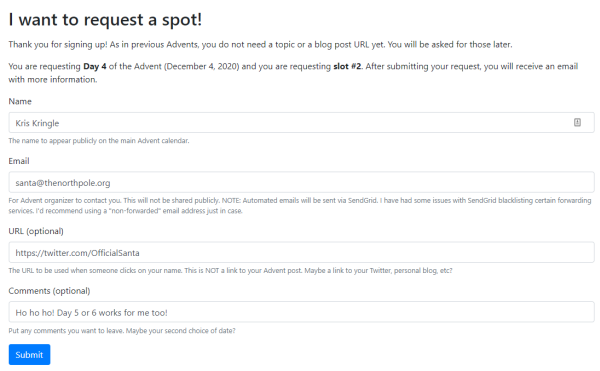
Step 3:
You should get a confirmation email. I will get an email too, so I can go in and approve your request (approval is a necessary, because there could be a date conflict, or there could be spammers, etc).
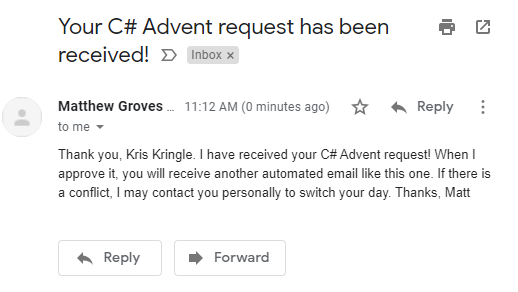
Step 4:
When approved, you will get another email. Approval should be pretty quick if I'm awake (I'm in the eastern US time zone).
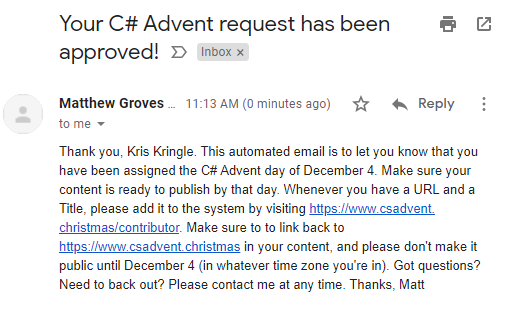
Step 5:
Create your content. Don't publish it until the day you selected. Make sure to link back to www.csadvent.christmas. At any point, you can login to the Contributors Area to supply a link and title of your content.
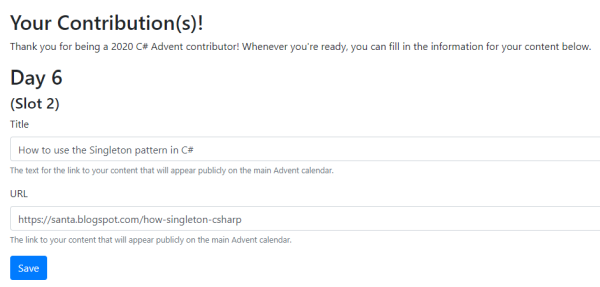
You do NOT have to do this until the day you picked. However! You will receive an automated email reminder 2 days ahead of time.
Step 6:
When it's your day, tell everyone about your article and the C# Advent! Tweet them! Submit others to Reddit! Facebook! LinkedIn! Whatever else! Let's show the world how great the C# community is! Please use the #csadvent hash tag when applicable.
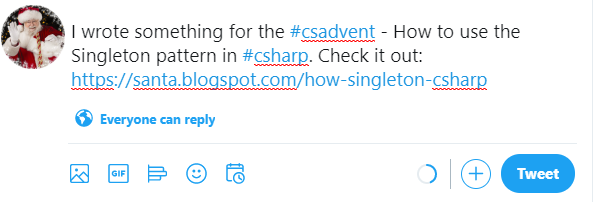
Thank you! Looking forward to another great Advent in 2020.
