Managing database migrations is an important part of a project. Everyone on the team needs to be on the same page when it comes to the database, while still having the ability to make database changes when necessary.
I've used a variety of tools to do this on various projects, but one tool that I especially like is Fluent Migrator.
The idea with Fluent Migrator is to create a series of classes that create and modify the database schema (and data). Each class represents a single "migration" (in the sense that you are "migrating" from an empty database to a database with something in it). Here's an example of a migration that I might create if I were creating a table to store user information:
Several things to note:
Fluent syntax. This just means that you can chain stuff together in a natural and fluent way (see NDecision, Fluent NHibernate, Fluent Validation, etc for other examples). This was kinda a "trend" for a while in C# projects, but it does make sense in a number of contexts. The goal is to make the API discoverable and easy to use and also to make the code easier to read. Note that there are some sensible defaults when you create columns, but it never hurts to be explicit.
Migration attribute and Migration base class. This attribute and base class needs to be on each migration class. The number in the attribute determines the order in which the migrations will be executed (we only have 1 so far, but the next one would be 2, for instance).
Up and Down. Override the "Up" method to put in the code that will create/alter the database. Override the "Down" method to put in the code that will revert the changes made in the "Up" method. In some cases, it may not make sense to create a "Down".
Okay, let's say I create that migration, execute it (more on how to execute it later) against a database, write some code that uses that table, and check everything in. The next day, I learn that I need to create an optional "url" field for users. To do that, I'll create another migration class (I'm not editing the existing migration).
These migrations get compiled into a plain DLL, so to actually execute them against a database, you'll need some sort of migration runner. I've been using the command line runner, but there are runners for NAnt, MSBuild, and Rake available too if you use any of those tools on your build server to automatically deploy the database migrations alongside your application.
My next step usually involves creating some convenience batch files to use the command line migration runner. You can use these locally while you develop, or possibly call them as part of your build process. Here's an example of a set of batch files that I use to "Up" my local database to run all the latest migrations and one to "Down" my migration back a number of steps (both of these operations are very common while developing).
I put these in the project, but I always have them deploy to the bin folder (where the compiled migrations are). You could do it vice versa if you want.
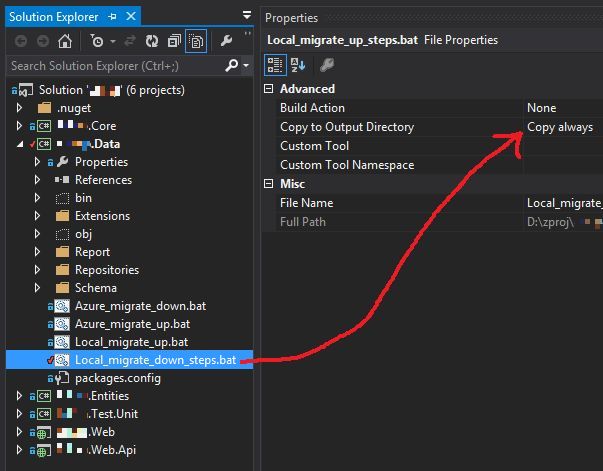
So that's it. Works against SQL 2012 and SQL Azure, in case you were wondering.
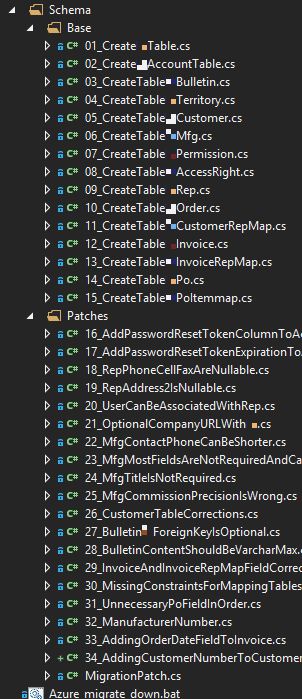
One other thing I do for the sake of organization is that I name all my migration files like NN_MigrationName. When I look at the list of files, I'll see them in migration order. Here's a screenshot from a real project of mine:
Welcome back to another "Weekly Concerns" (after skipping a week). This is a post-a-week series of interesting links, relevant to programming and programmers. You can check out previous Weekly Concerns posts in the archive.
- If you haven't seen Seth Petry-Johnson's Patterns of Effective Test Setup presentation yet, you should at least check out his slides.
- Source code for MS-DOS and Word for Windows is now available.
- You can play Missile Command with a YouTube video. Just go to any YouTube video, like this one, and type "1980".
- Mark Greenway and myself did an introductory presentation on WordPress with Azure through the MVP Mentor program. A recording of WordPress with Azure is now available.
If you have an interesting link that you'd like to see in Weekly Concerns, leave a comment or contact me.
In the last post, we started using ServiceBase as a way to more generally address the services and use the callback to report errors to the UI.
What happens if I put the aspect on a method in a class that doesn't inherit from ServiceBase (because either I forgot, or I put an aspect on a class outside of the service layer by mistake)? Exceptions will be swallowed, not reported, and probably cause issues elsewhere in the project.
One approach would be to change the case from "args.Instance as ServiceBase" to "(ServiceBase)args.Instance". At least then, I'll get a runtime error about casting (but only if there's an exception). With PostSharp, we can do better than that.
In fact, remember when I said that PostSharp aspects have to be marked as [Serializable]? This is because, as compile time, PostSharp instantiates those aspect objects and serializes them to be used later at runtime. BUT, since the aspect is being instantiated anyway, PostSharp also does a couple of other optional steps: it can do some compile-time initialization (to avoid runtime reflection, for instance), and it can do some compile-time validation.
That's right, we can put some code in the aspect that can check to make sure that we're applying the aspect correctly. If we aren't, it will give us a compile-time error. We could check, for instance, that the aspect is being applied to a method in a class that inherits ServiceBase.
This code will only be executed at compile-time. If the declaring type (the class that the method is in) does not inherit from ServiceBase, then PostSharp will write out an error at compile time:
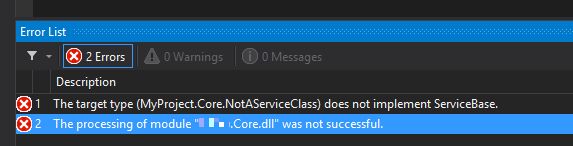
So now if I ever forget to use ServiceBase, or I use this aspect in the wrong place, I'll know right when I'm compiling. And because of this validation, I can also confidently change the cast from "args.Instance as ServiceBase" to "(ServiceBase)args.Instance", knowing that if the project compiles, that cast will never fail.
How are we doing:
- This only works for ITerritoryService--what about the other services?
- Swallowing exceptions: we should at least be logging the exception, not just ignoring it.
- If the method has a return type, then it's returning null. If it's meant to return a reference type, that's probably fine, but what if it's returning a value type?
- What if it's returning a collection, and the UI assumes that it will get an empty collection instead of a null reference?
- Do we really want to return the exception message to the user?
- What if I forget to use ServiceBase as a base class on a new service? <- We just took care of this
Next time we'll look at actually logging the exception.
In the previous post, we got the aspect to communicate with the service object by using args.Instance. But it only really works for one service: TerritoryService.
How can we get it to work with other services?
One approach would be to add a bunch of casts and if-statements:
I don't like that approach much. Another approach would be to create a base class that all our service classes would inherit from. I generally try to avoid this approach as much as possible, but I think it makes sense in this case. We could create an interface, like IHasValidationCallback, but let's take it one step further and create an abstract base class that already contains the implementation.
Now that the TerritorySerivce (and our other services) have a ServiceBase base class, we can update the aspect to use ServiceBase.
And there you have it: as long as all the services in the namespace inherit from ServiceBase, this will work.
So I think we're making progress, but let's review the issues from last time:
- This only works for ITerritoryService--what about the other services? We just addressed this one.
- Swallowing exceptions: we should at least be logging the exception, not just ignoring it.
- If the method has a return type, then it's returning null. If it's meant to return a reference type, that's probably fine, but what if it's returning a value type?
- What if it's returning a collection, and the UI assumes that it will get an empty collection instead of a null reference?
- Do we really want to return the exception message to the user?
- NEW ISSUE: What if I forget to use ServiceBase as a base class on a new service?
Yep, we fixed one issue, but we really just shifted the problem to a base class that could easily be overlooked. Next time, let's see if we can get PostSharp to help us with that.
My new employer is Heuristic Solutions, and I am starting as the Software Solutions Lead today.

(I blurred the phone numbers and email address to avoid spam, but if you want to know what they are, just contact me).
Heuristic Solutions made me an offer that was just too good to turn down. We are a very small consulting firm, but also a product company. Heuristic Solutions is the company behind Learning Builder, a leading online credentialing management platform. However, I won't be on the product team. Instead, I'm coming on to help grow the consulting practice. In my view, a consultant company that also builds and sells a product (or a product company that also has a consulting practice, depending on how you look at it) is in a very strong position. I won't go into it too much, but imagine the talent that you can develop and attract when you can offer experience in a variety of technologies and industries, and then apply that experienced talent to your own product. And, more practically, think about the diversification of revenue sources.
Anyway, the opportunity to lead the consulting practice for a company positioned like Heuristic is positioned is just something that I couldn't say no to. I'll still be working remotely (though probably travelling a bit more than I was with Zimbra). Just like when I started with Telligent, I'm a little scared! I have some pretty ambitious goals for myself and for Heuristic, and I've left one of the best jobs of my career to take on a whole bunch of new responsibilities and risks.
However, it's a challenge that I think I'm ready for. I'll be a coworker with the inimitable Seth Petry-Johnson (though he's on the product side), and after extensive talks with founder Christopher Butcher, I'm very happy about the Heuristic philosophy and the direction that he wants to take Heuristic.
(I'm even fond of the company name: Heuristic Solutions. In software, there is no silver bullet that solves everything; there is a instead a series of heuristics that usually represent the optimal course of action. These heuristics almost never become "laws", and always remain open to augmentation.)
