[Migration(1)]
public class Migration001_CreateInitialScopeAndCollection : Migrate
{
public override void Up()
{
Create.Scope("myScope")
.WithCollection("myCollection1");
}
public override void Down()
{
Delete.Scope("myScope");
}
}Posts tagged with 'data'
This blog post is a part of the 2022 C# Advent. Every day of Advent, two contributions from C# enthusiasts are revealed. Thanks for reading, and Merry Christmas!
I’ve written about How I use Fluent Migrator and Lessons learned about Fluent Migrator. I like using Fluent Migrator when I worked with relational databases.
However, I spend most of my time working with the NoSQL document database Couchbase, these days. If the idea of Fluent Migrator for Couchbase sounds interesting, read on!
What are database migrations?
Database migrations (not to be confused with data migrations) are a series of scripts/definitions that build the structure of a database. For instance, the first script could create 15 tables. The next script might alter a table, or add a 16th table. And so on.
Why are they important?
Having database migrations are important because they make sure anyone interacting with the database is on the same page, whether they’re working on a local database, test database, staging database, production, etc. Migrations can be part of the CI/CD process, as well.
What good is that for NoSQL?
If you’re not familiar with NoSQL, you might think that migrations wouldn’t make any sense. However, NoSQL databases (especially document databases), while flexible, are not devoid of structure. For instance, in place of Database/Schema/Table/Row, Couchbase has the concepts of Bucket/Scope/Collection/Document that roughly correspond.
It’s true that a NoSQL migration would not have as much predefined detail (there’s nowhere to specify column names and data types, for instance), but the benefits of migrations can still help developers working with Couchbase.
Introducing NoSqlMigrator for Couchbase
I’ve created a brand new project called NoSqlMigrator, to offer the same style of migration as Fluent Migrator.
Important notes:
-
This is not a fork or plugin of Fluent Migrator. It’s a completely separate project.
-
This is not an official Couchbase, Inc product. It’s just me creating it as an open source, community project.
-
It’s very much a WIP/alpha release. Please leave suggestions, criticisms, PRs, and issues!
Setting up migrations in C#
The process is very similar to Fluent Migrator.
-
Create a project that will contain your migration classes (you technically don’t have to, but I recommend it).
-
Add NoSqlMigrator from NuGet to that project.
-
Create classes that inherit from
Migratebase class. Define anUpandDown. Add aMigrationattribute and give it a number (typically sequential). -
When you’re ready to run migrations, you can use the CLI migration runner, available as a release on GitHub, or you can use the
MigrationRunnerclass, and run the migrations from whatever code you like. (I recommend the CLI).
Currently, NoSqlMigrator only supports Couchbase. Unlike the relational world, there is a lot of variance in structure and naming in the NoSQL world, so adding support for other NoSQL databases might be awkward (But I won’t rule that out for the far future).
Creating your first migration
Here’s an example of a migration that creates a scope and a collection (a bucket must already exist) when going "Up". When going down, the scope is deleted (along with any collections in it).
If you are new to migrations, the Down can sometimes be tricky. Not everything can be neatly "downed". However, I find that I tend to only use Down during development, and rarely does it execute in test/integration/production. But it is possible, so do your best when writing Down, but don’t sweat it if you can’t get it perfect.
Running the migration
Here’s an example of using the command line to run a migration:
> NoSqlMigrator.Runner.exe MyMigrations.dll couchbase://localhost Administrator password myBucketNameThat will run all the Up implementations (that haven’t already been run: it keeps track with a special document in Couchbase).
You can also specify a limit (e.g. run all migrations up to/down from #5) and you can specify a direction (up/down). Here’s an example of running Up (explicitly) with a limit of 5:
> NoSqlMigrator.Runner.exe MyMigrations.dll couchbase://localhost Administrator password myBucketName -l 5 -d UpMore features for NoSQL migrations
Here are all the commands currently available:
-
Create.Scope
-
Create.Collection
-
Create.Index
-
Delete.Scope
-
Delete.Collection
-
Delete.FromCollection
-
Delete.Index
-
Insert.IntoCollection
-
Execute.Sql
-
Update.Document
-
Update.Collection
I’m working on a few more, and I have some GitHub issues listing commands that I plan to add. But if you can think of any others, please create an issue!
Tips and Conclusion
Many of the Lessons learned still apply to NoSqlMigrator.
In that post, I mention Octopus, but imagine any CI/CD/deployment tool of your choice in its place (e.g. Jenkins, GitHub Actions, etc).
I think NoSqlMigrator can be a very handy tool for keeping databases in sync with your team, checking knowledge into source control, and providing a quick way to get a minimum database structure built, to make your day of coding a little easier.
Please give it a try in your own project! If you’ve not used Couchbase, check out a free trial of Couchbase Capella DBaaS.

Jeffrey Miller is using Neo4j. This episode is sponsored by Smartsheet.
Show Notes:
-
CosmosDB on Azure
-
Magic: The Gathering is a collectible card game that I once sunk a lot of money into
-
Michael Hunger developer relations with Neo4j
-
link: Presentation slides by Jeffrey
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Music is by Joe Ferg, check out more music on JoeFerg.com!
This is a repost that originally appeared on the Couchbase Blog: SQL to JSON Data Modeling with Hackolade.
SQL to JSON data modeling is something I touched on in the first part of my "Moving from SQL Server to Couchbase" series. Since that blog post, some new tooling has come to my attention from Hackolade, who have recently added first-class Couchbase support to their tool.
In this post, I’m going to review the very simple modeling exercise I did by hand, and show how IntegrIT’s Hackolade can help.
I’m using the same SQL schema that I used in the previous blog post series; you can find it on GitHub (in the SQLServerDataAccess/Scripts folder).
Review: SQL to JSON data modeling
First, let’s review, the main way to represent relations in a relational database is via a key/foreign key relationship between tables.
When looking at modeling in JSON, there are two main ways to represent relationships:
-
Referential - Concepts are given their own documents, but reference other document(s) using document keys.
-
Denormalization - Instead of splitting data between documents using keys, group the concepts into a single document.
I started with a relational model of shopping carts and social media users.
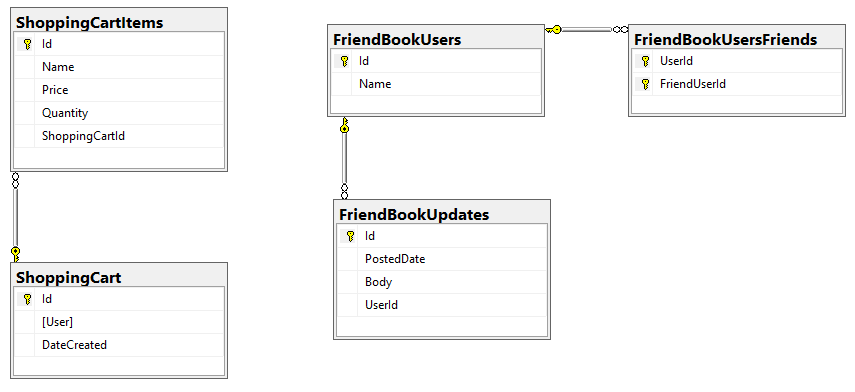
In my example, I said that a Shopping Cart - to - Shopping Cart Items relationship in a relational database would probably be better represented in JSON by a single Shopping Cart document (which contains Items). This is the "denormalization" path. Then, I suggested that a Social Media User - to - Social Media User Update relationship would be best represented in JSON with a referential relationship: updates live in their own documents, separate from the user.
This was an entirely manual process. For that simple example, it was not difficult. But with larger models, it would be helpful to have some tooling to assist in the SQL to JSON data modeling. It won’t be completely automatic: there’s still some art to it, but the tooling can do a lot of the work for us.
Starting with a SQL Server DDL
This next part assumes you’ve already run the SQL scripts to create the 5 tables: ShoppingCartItems, ShoppingCart, FriendBookUsers, FriendBookUpdates, and FriendBookUsersFriends. (Feel free to try this on your own databases, of course).
The first step is to create a DDL script of your schema. You can do this with SQL Server Management Studio.
First, right click on the database you want. Then, go to "Tasks" then "Generate Scripts". Next, you will see a wizard. You can pretty much just click "Next" on each step, but if you’ve never done this before you may want to read the instructions of each step so you understand what’s going on.
Finally, you will have a SQL file generated at the path you specified.
This will be a text file with a series of CREATE and ALTER statements in it (at least). Here’s a brief excerpt of what I created (you can find the full version on Github).
CREATE TABLE [dbo].[FriendBookUpdates](
[Id] [uniqueidentifier] NOT NULL,
[PostedDate] [datetime] NOT NULL,
[Body] [nvarchar](256) NOT NULL,
[UserId] [uniqueidentifier] NOT NULL,
CONSTRAINT [PK_FriendBookUpdates] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
-- etc...By the way, this should also work with SQL Azure databases.
Note: Hackolade works with other types of DDLs too, not just SQL Server, but also Oracle and MySQL.
Enter Hackolade
This next part assumes that you have downloaded and installed Hackolade. This feature is only available on the Professional edition of Hackolade, but there is a 30-day free trial available.
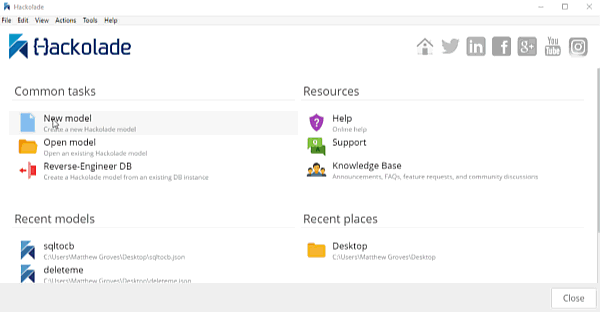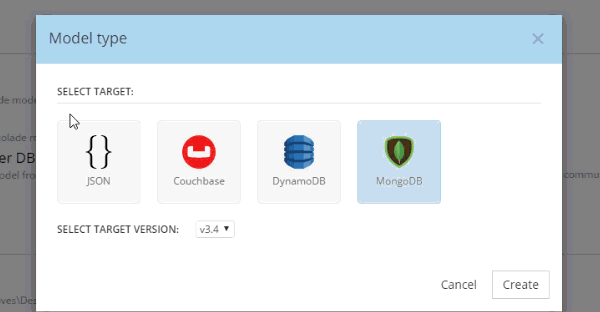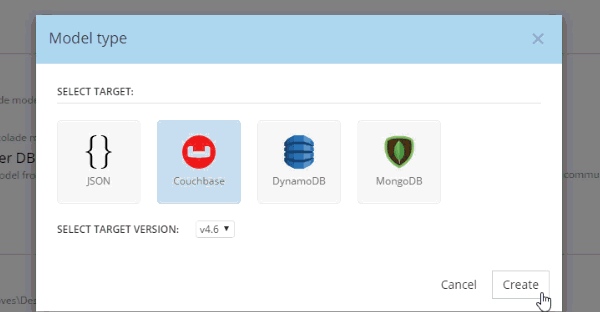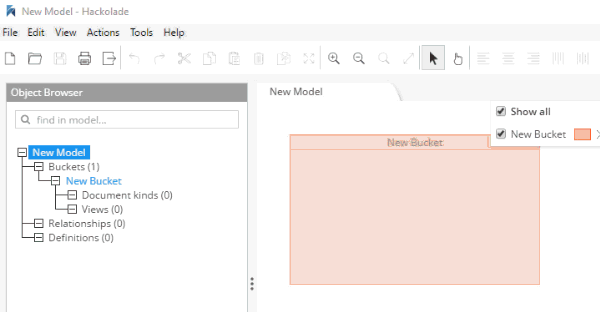
Once you have a DDL file created, you can open Hackolade.
In Hackolade, you will be creating/editing models that correspond to JSON models: Couchbase (of course) as well as DynamoDB and MongoDB. For this example, I’m going to create a new Couchbase model.
At this point, you have a brand new model that contains a "New Bucket". You can use Hackolade as a designing tool to visually represent the kinds of documents you are going to put in the bucket, the relationships to other documents, and so on.
We already have a relational model and a SQL Server DDL file, so let’s see what Hackolade can do with it.
Reverse engineer SQL to JSON data modeling
In Hackolade, go to Tools → Reverse Engineer → Data Definition Language file. You will be prompted to select a database type and a DDL file location. I’ll select "MS SQL Server" and the "script.sql" file from earlier. Finally, I’ll hit "Ok" to let Hackolade do its magic.

Hackolade will process the 5 tables into 5 different kinds of documents. So, what you end up with is very much like a literal translation.
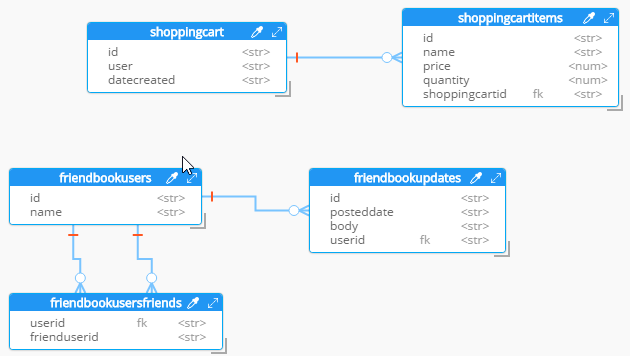
This diagram gives you a view of your model. But now you can think of it as a canvas to construct your ultimate JSON model. Hackolade gives you some tools to help.
Denormalization
For instance, Hackolade can make suggestions about denormalization when doing SQL to JSON data modeling. Go to Tools→Suggest denormalization. You’ll see a list of document kinds in "Table selection". Try selecting "shoppingcart" and "shoppingcartitems". Then, in the "Parameters" section, choose "Array in parent".
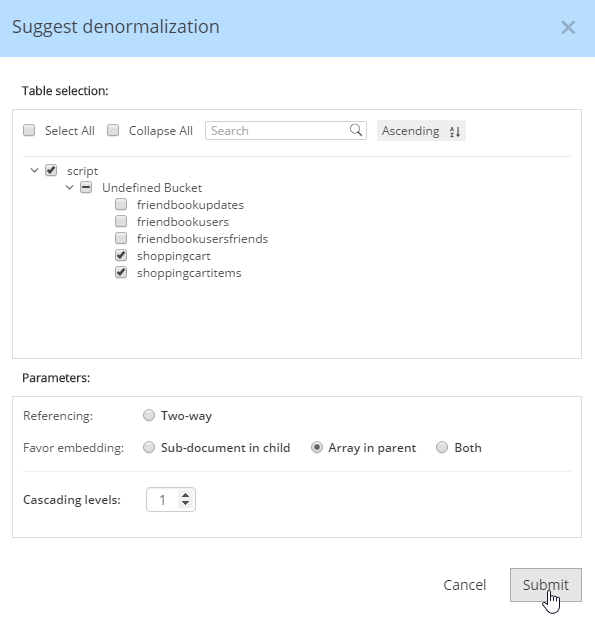
After you do this, you will see that the diagram looks different. Now, the items are embedded into an array in shoppingcart, and there are dashed lines going to shoppingcartitems. At this point, we can remove shoppingcartitems from the model (in some cases you may want to leave it, that’s why Hackolade doesn’t remove it automatically when doing SQL to JSON data modeling).
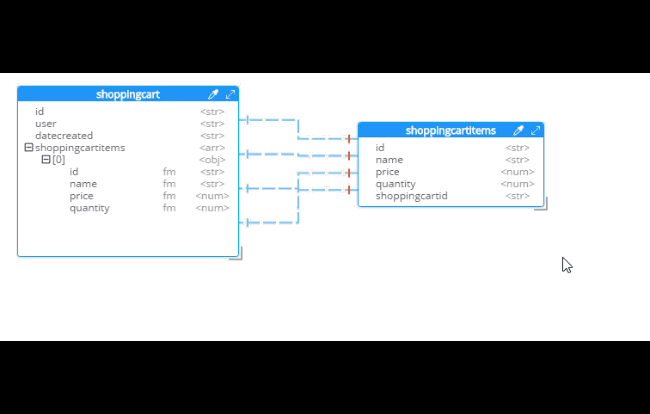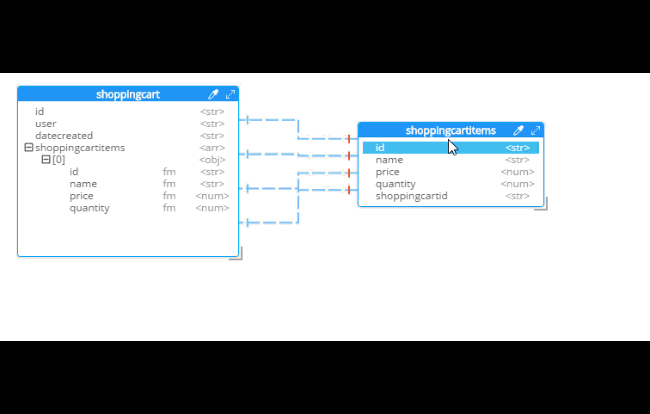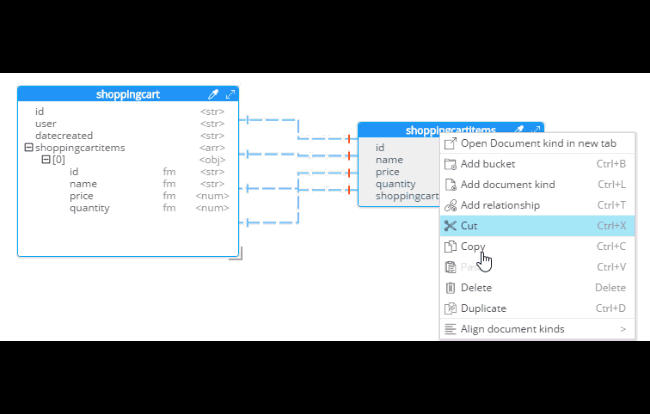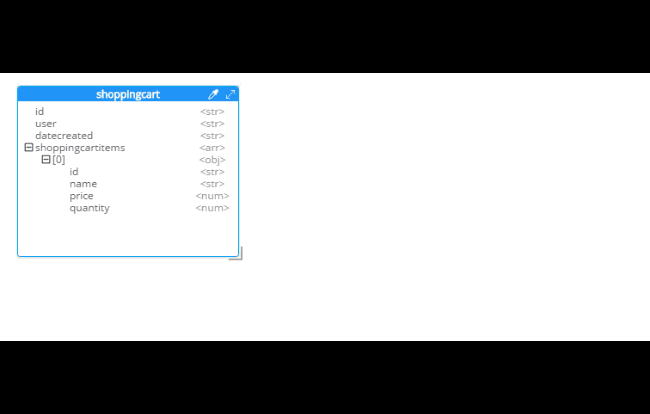
Notice that there are other options here too:
-
Embedding Array in parent - This is what was demonstrated above.
-
Embedding Sub-document in child - If you want to model the opposite way (e.g. store the shopping cart within the shopping cart item).
-
Embedding Both - Both array in parent and sub-document approach.
-
Two-way referencing - Represent a many-to-many relationship. In relational tables, this is typically done with a "junction table" or "mapping table"
Also note cascading. This is to prevent circular referencing where there can be a parent, child, grandchild, and so on. You select how far you want to cascade.
More cleanup
There are a couple of other things that I can do to clean up this model.
-
Add a 'type' field. In Couchbase, we might need to distinguish shoppingcart documents from other documents. One way to do this is to add a "discriminator" field, usually called 'type' (but you can call it whatever you like). I can give it a "default" value in Hackolade of "shoppingcart".
-
Remove the 'id' field from the embedded array. The SQL table needed this field for a foreign key relationship. Since it’s all embedded into a single document, we no longer need this field.
-
Change the array name to 'items'. Again, since a shopping cart is now consolidated into a single document, we don’t need to call it 'shoppingcartitems'. Just 'items' will do fine.

Output
A model like this can be a living document that your team works on. Hackolade models are themselves stored as JSON documents. You can share with team members, check them into source control, and so on.
You can also use Hackolade to generate static documentation about the model. This documentation can then be used to guide the development and architecture of your application.
Go to File → Generate Documentation → HTML/PDF. You can choose what components to include in your documentation.
Summary
Hackolade is a NoSQL modeling tool created by the IntegrIT company. It’s useful not only in building models from scratch, but also in reverse engineering for SQL to JSON data modeling. There are many other features about Hackolade that I didn’t cover in this post. I encourage you to download a free trial of Hackolade today. You can also find Hackolade on Twitter @hackolade.
If you have questions about Couchbase Server, please ask away in the Couchbase Forums. Also check out the Couchbase Developer Portal for more information on Couchbase for developers. Always feel free to contact me on Twitter @mgroves.
This is a repost that originally appeared on the Couchbase Blog: .NET Core List, Queue, and Dictionary Data Structures backed by Couchbase.
The addition of the sub-document API to Couchbase 4.5 has paved the way for efficient data structure support in Couchbase.
In this blog post, I’m going to show a demo of three types of data structures you can use with the Couchbase .NET SDK:
-
List - a list of objects, basically a List<T> backed by Couchbase
-
Queue - a queue of objects, basically a Queue<T> backed by Couchbase
-
Dictionary - a dictionary of objects, basically a Dictionary<K,T> backed by Couchbase
I’ll also discuss a little bit how this works behind the scenes.
You can play along at home if you like. The source code for this blog is available on GitHub, and Couchbase Server is free to download (developer previews of version 5 are currently available monthly).
List
A List<T> is a .NET data structure that is held in memory. With the data structures provided by the Couchbase .NET SDK, you can store it in a Couchbase document.
To create a Couchbase-backed List:
var list = new CouchbaseList<dynamic>(bucket, "myList");The string "myList" corresponds to the key for the document that will contain the list. When using CouchbaseList<T>, a single document with that key will be created (if one doesn’t exist already). If a document by that key already exists, CouchbaseList will use it.
You can now add/remove items from the list and that will all be persisted to the document. You can also perform other operations like getting a count of the items in the list.
// add 10 objects to the list
for(var i = 0; i < 10; i++)
list.Add(new { num = i, foo = "bar" + Guid.NewGuid()});
// remove an item from the list by index
list.RemoveAt(5);
// show an item from the list by index
Console.WriteLine("5th item in the list: " + list[5].foo + " / " + list[5].num);The above code would result in a document with a key "myList" that looks like below. Notice that the item with num of 5 is not listed, because it was removed.
There’s something subtle in the above example that needs to be pointed out. Notice that I used var item = list[5]; and then item.foo and item.num in the WriteLine. If I used list[5].foo and list[5].num directly, that would result in two different subdocument calls to Couchbase. Not only is this less than optimal efficiency, but it’s possible for the values to change between the two calls.
[
{
"num": 0,
"foo": "bara1fd74ee-a790-4a0f-843c-abe449cb8b1d"
},
{
"num": 1,
"foo": "bardc1d8f9a-4e93-46f9-b8ae-ec036743869e"
},
{
"num": 2,
"foo": "bar9a60abe9-1e04-4fba-bd1f-f1ec39d69f56"
},
{
"num": 3,
"foo": "bar9566605b-7abf-4a0c-aa9d-63b98ce86274"
},
{
"num": 4,
"foo": "bar6261323f-de50-42a7-a8a7-6fcafb356deb"
},
{
"num": 6,
"foo": "bar13832bcb-2aa0-491a-a01f-1d496f999ffc"
},
// ... etc ...
]Queue
Very similar to List, you can create a Couchbase-backed queue:
var queue = new CouchbaseQueue<dynamic>(bucket, "myQueue");A queue is stored just like a list. The difference is that the ordering is significant, and this is reflected by the operations you perform on a queue: Enqueue and Dequeue.
for(var i = 0; i < 3; i++)
queue.Enqueue(new { num = i, foo = "baz" + Guid.NewGuid()});
// dequeue
var item = queue.Dequeue();
Console.WriteLine("item num " + item.num + " was dequeued. There are now " + queue.Count + " items left in the queue.");The above code would result in a document with a key "myQueue" (see JSON below). Notice there is no object in the array with num "0" because it was dequeued.
[
{
"num": 1,
"foo": "baz64bb62b6-bf23-4e52-b584-d2fa02accce6"
},
{
"num": 2,
"foo": "baz0a160bd9-aa7b-4c45-9e19-d1a3d982a554"
}
]Dictionary
Hopefully you’re seeing a pattern now. To create a dictionary:
var dict = new CouchbaseDictionary<string,dynamic>(bucket, "myDict");Again, a document will be created with the given key. The operations that can be performed include Add, Remove, and the indexer [] operation.
for(var i = 0; i < 5; i++)
dict.Add("key" + Guid.NewGuid(), new { num = i, foo = "qux" + Guid.NewGuid()} );
// print out keys in the dictionary
Console.WriteLine("There are " + dict.Keys.Count + " keys in the dictionary.");
foreach(var key in dict.Keys)
Console.WriteLine("key: " + key + ", value.num: " + dict[key].num);A dictionary document looks like:
{
"key5aa2520d-123c-4fca-b444-b0cb8846d46e": {
"num": 0,
"foo": "qux93b197dc-f175-4246-a38d-7b080eb9bea0"
},
"key55dee298-14c6-4da7-97a8-66c69d7e8a70": {
"num": 1,
"foo": "quxa593ee4c-682c-402d-887b-3f09f029e9b6"
},
"key3386afcf-7b70-4e4d-b9ae-6defbca33fe7": {
"num": 2,
"foo": "qux1259ae94-1008-4e1f-86a1-bfbd0873b09b"
},
"key2bc8c451-f125-4282-9fb4-7ea15f4b3168": {
"num": 3,
"foo": "qux1b6fb62b-9918-46dc-9a2f-610a55d017ef"
},
"key3f7041f3-abd3-49c7-a373-454cbd2ac0fc": {
"num": 4,
"foo": "qux0a87655f-197d-4fb2-8a54-b1de6e288de4"
}
}A note about C# dynamic: I used dynamic to keep the code samples short and simple. In your application, you are probably better off using a real defined C# type. It all gets serialized to JSON in Couchbase, of course.
Behind the scenes
Before the subdocument API was released in Couchbase Server 4.5, these data structures were possible, of course. The catch was that you would be loading up the entire document, putting it in a list, making changes to the list, and then saving the entire document. If you have large data structures, but are only reading or making changes to a single item, this would often result in wasted time and wasted bandwidth and possibly increased contention.
The subdocument-API (which you can use directly; I covered it in the Sub-document API in Couchbase Server 4.5 with the .NET SDK (revisited) blog post) is used behind the scenes in CouchbaseList, CouchbaseQueue, and CouchbaseDictionary. So when you add an item to a CouchbaseList, for instance, only that item is being sent over the wire, not the entire list.
Some operations will still need to get the entire document. For instance, iterating through a collection using a foreach loop will retrieve the full document. Removing an item from a list will result in the full document being scanned. But if sub-document operations come along in the future to support those actions, the SDK implementations will be updated accordinging.
Summary
These data structures are another tool to help you manage your data. Since they use the sub-document API, they are generally more performant than a whole-document approach. For more detail, check out the Data Structures documentation.
Have questions? Feedback? Need help? Please visit our forums, ping me on Twitter @mgroves, or leave a comment.

Dan Shultz is using d3.js, dc.js, and other tools to visualize data.
Show notes:
- d3js.org - Data Driven Documents
- dc.js - Dimensional Charting
- Highcharts / AnyChart
- Parallel Coordinate Chart - I found an interesting example at Columbia.edu.
- Dashing D3 - newsletter, training, tutorials
- Dan's blog: Dan vs Machine
- Dan's employer: Clarivoy
He has some apps in the various markets, check them out:
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Theme music is "Crosscutting Concerns" by The Dirty Truckers, check out their music on Amazon or iTunes.
